(P1) LangChain
涉及内容
- langchain v0.1.0 preview blog (2023/12/12)
- langchain v 0.1.0 blog (2024/01/08), 里面也提及了许多使用 Langchain 来构建的项目.
langchain-corecontains simple, core abstractions that have emerged as a standard, as well as LangChain Expression Language as a way to compose these components together. This package is now at version 0.1 and all breaking changes will be accompanied by a minor version bump.
langchain-communitycontains all third party integrations. We will work with partners on splitting key integrations out into standalone packages over the next month.
langchaincontains higher-level and use-case specific chains, agents, and retrieval algorithms that are at the core of your application’s cognitive architecture. We are targeting a launch of a stable 0.1 release for langchain in early January.
libs/
- langchain/
- core/langchain_core/ # 关键抽象, 尽量少包含三方库
- community/langchain_community/ # ??
- partners/
- openai/langchain_openai/ # 集成组件, 一般是对三方库的简单包装
- anthropic/langchain_anthropic/
- cli/langchain_cli/
- experimental/langchain_experimental/ # ?? 实验组件, 可忽略?
python import 语句的准则 (笔者观点):
- 自定义组件一般
import langchain_core - 使用官方的组合组件的方式一般用
import langchain - 官方已支持的第三方集成优先用 partner, 然后考虑
langchain_community
from langchain_openai.chat_models import ChatOpenAI # 最优先, 但不是每个第三方集成都会做成一个单独的包
from langchain_community.llms.openai import OpenAIChat # 次优先
from langchain.llms.openai import OpenAIChat # 本质上与第二种一致, 但这只是官方的兼容性保证的做法, 不推荐
Tutorial
Langchain 的本质就是以一种作者认为的模块化的方式进行提示工程.
引用: https://python.langchain.com/docs/get_started/quickstart
LangChain provides many modules that can be used to build language model applications. Modules can be used as standalones in simple applications and they can be composed for more complex use cases. Composition is powered by LangChain Expression Language (LCEL), which defines a unified
Runnableinterface that many modules implement, making it possible to seamlessly chain components.The simplest and most common chain contains three things:
LLM/Chat Model: The language model is the core reasoning engine here. In order to work with LangChain, you need to understand the different types of language models and how to work with them. Prompt Template: This provides instructions to the language model. This controls what the language model outputs, so understanding how to construct prompts and different prompting strategies is crucial. Output Parser: These translate the raw response from the language model to a more workable format, making it easy to use the output downstream.
理解这段话需要借助一下继承关系图
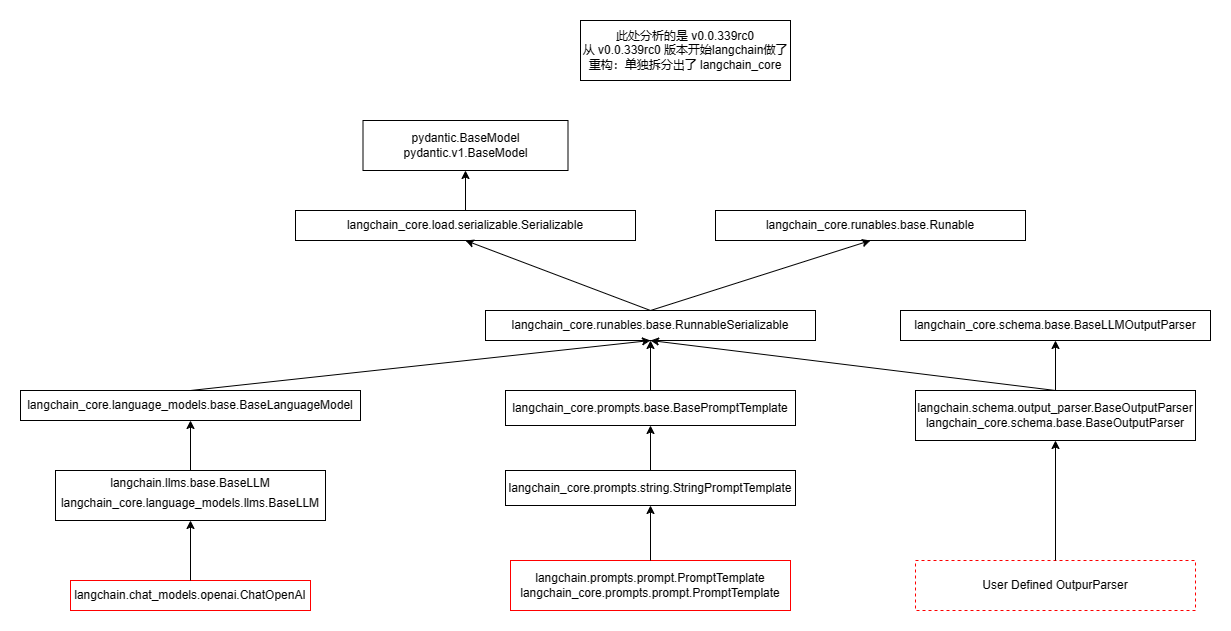
继承关系图说明: 以红色作为框线的方框代表的是实际可运行的类(其余均为抽象类), 由于 langchain>=0.0.339rc0 (2023/11/22) 开始, langchain 代码库进行了一些重构, 主要是将一部分内容单独抽出来放在了 langchain_core 模块中, 同一个框中的两个类是别名关系.
LLM/Chat Model 的一个实际例子是 ChatOpenAI 类, Prompt Template 的一个实际例子是 PromptTemplate 类, 而 Output Parser 需要用户自己继承自 BaseOutputParser. 而这三类东西都继承自 Runnable 抽象类, 这种继承自 Runnable 的类都称为 LCEL. 所以如果希望研究源码, 可以先研究 Runnable 抽象类. 在此之前先看一些例子:
以下例子参考: https://python.langchain.com/docs/get_started/quickstart
例子1 (llm, prompt, output parser, LCEL basics)
参考自: https://python.langchain.com/docs/get_started/quickstart#llm-chain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
llm = ChatOpenAI(openai_api_key="sk-xx")
output_parser = StrOutputParser()
chain = prompt | llm | output_parser # LCEL
s: str = chain.invoke({"input": "how can langsmith help with testing?"})
chain.first # prompt
chain.last # output_parser
chain.middle # [llm]
chain.steps # [prompt, llm, output_parser]
例子 2 (模型自定义, langserve)
pip install langchain langserve sse_starlette
使用 python serve.py 运行, 界面在 http://localhost:8000/chain/playground/
#!/usr/bin/env python
# serve.py
from typing import Any, List, Mapping, Optional
from fastapi import FastAPI
from langchain.schema import BaseOutputParser
from langserve import add_routes
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain.llms.base import LLM
from langchain.prompts import PromptTemplate
class CustomLLM(LLM):
n: int
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
if stop is not None:
raise ValueError("stop kwargs are not permitted.")
return prompt[:self.n]
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"n": self.n}
class CustomOutputParser(BaseOutputParser[str]):
"""Parse the output of an LLM call to a comma-separated list."""
def parse(self, text: str) -> str:
"""Parse the output of an LLM call."""
return text
prompt_template = PromptTemplate.from_template("instruction: {instruction}\nquestion{q}")
llm = CustomLLM(n=30)
parser = CustomOutputParser()
chain = prompt_template | llm | parser
# chain.invoke({"instruction": "1234567890123", "q": "qa"})
# 2. App definition
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
# 3. Adding chain route
add_routes(
app,
chain,
path="/chain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
例子 3 (index, RAG)
参考自: https://python.langchain.com/docs/get_started/quickstart#retrieval-chain
PART 1
# pip install beautifulsoup4 faiss-cpu
from langchain_openai import OpenAIEmbeddings
from langchain_openai import ChatOpenAI
embeddings = OpenAIEmbeddings()
llm = ChatOpenAI()
from langchain_core.documents.base import Document
from typing import List
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = WebBaseLoader("https://docs.smith.langchain.com/overview")
# Document has two attrs: page_content: str, metadata: Dict
docs: List[Document] = loader.load() # metadata keys: ['source', 'title', 'description', 'language']
text_splitter = RecursiveCharacterTextSplitter()
documents: List[Document] = text_splitter.split_documents(docs) # metadata keys: ['source', 'title', 'description', 'language']
vector = FAISS.from_documents(documents, embeddings)
# vector.docstore._dict: Dict[str, Document] # {"ass": Document(...), "bss": Document(...)}
# vector.index_to_docstore_id: Dict[int, str] # {0: "ass", 1: "bss"}
# vector.index: faiss.swigfaiss_avx2.IndexFlatL2
继承关系图
# vector: FAISS
langchain_core.vectorstores.VectorStore(ABC):
langchain_community.vectorstores.FAISS(VectorStore)
# vector.docstore: InMemoryDocstore
langchain_community.docstore.base.AddableMixin(ABC): search, delete
langchain_community.docstore.base.Docstore(ABC): add
langchain_community.docstores.in_memory.InMemoryDocstore(Docstore, AddableMixin)
PART 2
# pip install grandalf
from langchain.chains.combine_documents import create_stuff_documents_chain
from langchain_core.prompts import ChatPromptTemplate
import langchain_core
prompt = ChatPromptTemplate.from_template("""Answer the following question based only on the provided context:
<context>
{context}
</context>
Question: {input}""")
document_chain: langchain_core.runnables.base.RunnableBinding = create_stuff_documents_chain(llm, prompt)
# 一些探索
document_chain.get_graph().nodes
document_chain.get_graph().edges
print(document_chain.get_graph().draw_ascii())
输出
# nodes:
{'10df13934301478abd3ba5dd8de10598': Node(id='10df13934301478abd3ba5dd8de10598', data=<class 'pydantic.v1.main.RunnableParallel<context>Input'>),
'a087b655b2cd4fb49951b3170874329d': Node(id='a087b655b2cd4fb49951b3170874329d', data=<class 'pydantic.v1.main.RunnableParallel<context>Output'>),
'24444bcbd4e04ac3b6b7a9b75ea70b2d': Node(id='24444bcbd4e04ac3b6b7a9b75ea70b2d', data=PromptTemplate(input_variables=['page_content'], template='{page_content}')),
'87f1b6b35bed4f128ecafb41c328ae45': Node(id='87f1b6b35bed4f128ecafb41c328ae45', data=RunnablePassthrough()),
'706cdd684df24146b0b8985fedf4312e': Node(id='706cdd684df24146b0b8985fedf4312e', data=ChatPromptTemplate(input_variables=['context', 'input'], messages=[HumanMessagePromptTemplate(prompt=PromptTemplate(input_variables=['context', 'input'], template='Answer the following question based only on the provided context:\n\n<context>\n{context}\n</context>\n\nQuestion: {input}'))])),
'19fc2995c60745509e4bdebc951e74f9': Node(id='19fc2995c60745509e4bdebc951e74f9', data=ChatOpenAI(client=<openai.resources.chat.completions.Completions object at 0x7f25b1e9f820>, async_client=<openai.resources.chat.completions.AsyncCompletions object at 0x7f25b1ebbcd0>, openai_api_key='sk-xxx', openai_proxy='')),
'82c0eea4218b4ba8ab35dc8a08364f6b': Node(id='82c0eea4218b4ba8ab35dc8a08364f6b', data=StrOutputParser()),
'e82fa2229583412eaf4cea0d32818487': Node(id='e82fa2229583412eaf4cea0d32818487', data=<class 'pydantic.v1.main.StrOutputParserOutput'>)}
# edges:
[Edge(source='418e866578f840c8b9e8954000a16883', target='e77a1ecf38c14457bd6606305bbf040b'),
Edge(source='e77a1ecf38c14457bd6606305bbf040b', target='09a9f05f03e540c3afb008d7eb4bcdfa'),
Edge(source='418e866578f840c8b9e8954000a16883', target='a424ccc59e3b4b4197333c6e2ee8dcf7'),
Edge(source='a424ccc59e3b4b4197333c6e2ee8dcf7', target='09a9f05f03e540c3afb008d7eb4bcdfa'),
Edge(source='09a9f05f03e540c3afb008d7eb4bcdfa', target='497f4a32536440319ad796fe51d26b47'),
Edge(source='497f4a32536440319ad796fe51d26b47', target='9ded27aa029d41a6a51e9a5af9600955'),
Edge(source='1fd84bd773be42a1911a64a1424af96c', target='ddf23954923f433ba714f6a29e2670d8'),
Edge(source='9ded27aa029d41a6a51e9a5af9600955', target='1fd84bd773be42a1911a64a1424af96c')]
# draw_ascii:
+------------------------+
| Parallel<context>Input |
+------------------------+
*** ***
** **
** **
+----------------+ +-------------+
| PromptTemplate | | Passthrough |
+----------------+ +-------------+
*** ***
** **
** **
+-------------------------+
| Parallel<context>Output |
+-------------------------+
*
*
*
+--------------------+
| ChatPromptTemplate |
+--------------------+
*
*
*
+------------+
| ChatOpenAI |
+------------+
*
*
*
+-----------------+
| StrOutputParser |
+-----------------+
*
*
*
+-----------------------+
| StrOutputParserOutput |
+-----------------------+
PART 3
from langchain_core.documents import Document
answer: str = document_chain.invoke({
"input": "how can langsmith help with testing?",
"context": [Document(page_content="langsmith can let you visualize test results")]
}) # answer: "Langsmith can help with testing by allowing users to visualize test results."
from langchain.chains import create_retrieval_chain
# VectorStoreRetriever 也继承自 langchain_core.runnables.base.Runnable
retriever: langchain_core.vectorstores.VectorStoreRetriever = vector.as_retriever()
retrieval_chain: langchain_core.runnables.base.RunnableBinding = create_retrieval_chain(retriever, document_chain)
response = retrieval_chain.invoke({"input": "how can langsmith help with testing?"})
print(response["answer"])
# "LangSmith can help with testing by providing various features ..."
print(retrieval_chain.get_graph().draw_ascii())
图示
+------------------------+
| Parallel<context>Input |
+------------------------+
*** ***
**** ***
** ****
+------------------------------+ **
| Lambda(lambda x: x['input']) | *
+------------------------------+ *
* *
* *
* *
+----------------------+ +-------------+
| VectorStoreRetriever | | Passthrough |
+----------------------+ *+-------------+
*** ***
**** ****
** **
+-------------------------+
| Parallel<context>Output |
+-------------------------+
*
*
*
+-----------------------+
| Parallel<answer>Input |
+-----------------------+*
**** *****
*** *****
** ******
+------------------------+ ***
| Parallel<context>Input | *
+------------------------+ *
*** *** *
** ** *
** ** *
+----------------+ +-------------+ *
| PromptTemplate | | Passthrough | *
+----------------+ +-------------+ *
*** *** *
** ** *
** ** *
+-------------------------+ *
| Parallel<context>Output | *
+-------------------------+ *
* *
* *
* *
+--------------------+ *
| ChatPromptTemplate | *
+--------------------+ *
* *
* *
* *
+------------+ *
| ChatOpenAI | *
+------------+ *
* *
* *
* *
+-----------------+ +-------------+
| StrOutputParser | | Passthrough |
+-----------------+ *****+-------------+
**** *****
*** ******
** ***
+------------------------+
| Parallel<answer>Output |
+------------------------+
例子 4 (langchainhub)
from langchain import hub
prompt = hub.pull("hwchase17/openai-functions-agent")
import pickle
with open("openai-functions-agent.pkl", "wb") as fw:
pickle.dump(prompt, fw)
import pickle
with open("openai-functions-agent.pkl", "rb") as fr:
reload_prompt = pickle.load(fr)
例子 5 (async & stream)
Python 脚本中
from langchain.chat_models import ChatOpenAI
import asyncio
async def main():
model = ChatOpenAI()
chunks = []
async for chunk in model.astream("hello. tell me something about yourself"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)
asyncio.run(main())
# 基本等价于:
# asyncio.get_event_loop().run_until_complete(main())
Jupyter 环境
jupyter 环境里可以直接将 async 关键字写在外层
from langchain.chat_models import ChatOpenAI
model = ChatOpenAI()
chunks = []
async for chunk in model.astream("hello. tell me something about yourself"):
chunks.append(chunk)
print(chunk.content, end="|", flush=True)
例子 6 (callbacks, TODO: 待解释)
参考: https://python.langchain.com/docs/expression_language/how_to/functions#accepting-a-runnable-config
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableConfig, RunnableLambda
import json
def parse_or_fix(text: str, config: RunnableConfig):
fixing_chain = (
ChatPromptTemplate.from_template(
"Fix the following text:\n\n```text\n{input}\n```\nError: {error}"
" Don't narrate, just respond with the fixed data."
)
| ChatOpenAI()
| StrOutputParser()
)
for _ in range(3):
try:
return json.loads(text)
except Exception as e:
text = fixing_chain.invoke({"input": text, "error": e}, config)
return "Failed to parse"
from langchain.callbacks import get_openai_callback
with get_openai_callback() as cb:
output = RunnableLambda(parse_or_fix).invoke(
"{foo: bar}", {"tags": ["my-tag"], "callbacks": [cb]}
)
print(output)
print(cb)
输出:
{'foo': 'bar'}
Tokens Used: 65
Prompt Tokens: 56
Completion Tokens: 9
Successful Requests: 1
Total Cost (USD): $0.00010200000000000001
例子 7 (LCEL Memory, redis)
参考: https://python.langchain.com/docs/expression_language/how_to/message_history
from typing import Optional
from langchain_community.chat_message_histories import RedisChatMessageHistory
from langchain_community.chat_models import ChatOpenAI
from langchain_core.chat_history import BaseChatMessageHistory
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.runnables.history import RunnableWithMessageHistory
REDIS_URL = "redis://localhost:6379/0"
prompt = ChatPromptTemplate.from_messages(
[
("system", "You're an assistant who's good at {ability}"),
MessagesPlaceholder(variable_name="history"),
("human", "{question}"),
]
)
chain = prompt | ChatOpenAI()
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: RedisChatMessageHistory(session_id, url=REDIS_URL, ttl=600), # 设置失效时间为 600 秒
input_messages_key="question",
history_messages_key="history",
)
chain_with_history.invoke(
{"ability": "math", "question": "What does cosine mean?"},
config={"configurable": {"session_id": "foobar"}},
)
# 可以尝试直接调 chain, 不会写 history
# messages = chain_with_history.get_session_history("foobar").messages
# chain.invoke(
# {
# "ability": "math",
# "question": "What's its inverse",
# "history": chain_with_history.get_session_history("foobar").messages # List[BaseMessage]
# }
# )
chain_with_history.invoke(
{"ability": "math", "question": "What's its inverse"},
config={"configurable": {"session_id": "foobar"}},
)
备注: 这个例子里 redis 侧实际发生的事情如下: langchain 的实现是用 lpush/lrange 来存储/获取键值对, 而不是使用 set/get 的方式
# docker run -d -p 6379:6379 -p 8001:8001 redis/redis-stack:latest
import redis
import json
from langchain_core.messages import messages_from_dict, message_to_dict
from langchain_core.messages import HumanMessage, AIMessage
REDIS_URL = "redis://localhost:6379/0"
redis_client = redis.from_url(url=REDIS_URL)
prefix = "message_store:"
session_id = "foobar"
# 追加历史:
message = HumanMessage(content='What does cosine mean?')
redis_client.lpush(prefix+session_id, json.dumps(message_to_dict(message)))
message = AIMessage(content='In mathematics, cosine (abbreviated as cos) is a trigonometric function that relates the angle of a right triangle to the ratio of the length of the adjacent side to the hypotenuse. It is defined as the ratio of the length of the side adjacent to an acute angle in a right triangle to the length of the hypotenuse. The cosine function is commonly used in geometry, physics, and engineering to solve problems related to angles and triangles.')
redis_client.lpush(prefix+session_id, json.dumps(message_to_dict(message)))
# 获取历史:
_items = redis_client.lrange(prefix+session_id, 0, -1)
items = [json.loads(m.decode("utf-8")) for m in _items[::-1]]
messages = messages_from_dict(items)
备注: 可以通过如下方式去掉对 redis 的依赖:
from langchain_community.chat_message_histories.in_memory import ChatMessageHistory
message_history = ChatMessageHistory()
chain_with_history = RunnableWithMessageHistory(
chain,
lambda session_id: message_history,
input_messages_key="question",
history_messages_key="history",
)
# invoke 之后可以通过这两种方案来看现有的历史
chain_with_history.get_session_history("foobar").messages # 通过 chain_with_history 拿到历史的做法
message_history.messages
例子 8 (强制结构化输出)
from langchain.pydantic_v1 import BaseModel, Field
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain.chains.openai_functions import create_structured_output_runnable
class ExecuteCode(BaseModel):
"""The input to the numexpr.evaluate() function."""
reasoning: str = Field(
...,
description="The reasoning behind the code expression, including how context is included, if applicable.",
)
code: str = Field(
...,
description="The simple code expression to execute by numexpr.evaluate().",
)
chat_llm = ChatOpenAI()
template = ChatPromptTemplate.from_messages(
[
"user", "{text}"
]
)
runnable = create_structured_output_runnable(ExecuteCode, chat_llm, template)
result = runnable.invoke({"input": "1+1"})
# ExecuteCode(reasoning='The user input is a simple addition operation.', code='1+1')
create_structured_ouput_runnable 的本质是:
runnable = template | chat_llm.bind(...) | get_openai_output_parser([ExecuteCode])
尤其注意 chat_llm.bind 一共绑定了两个参数 functions 和 function_call (现在更推荐用 tools 和 tool_choice): 其中前者代表了模型可以使用的工具的描述, 而后者一般是不显式指定的, 不显式指定时模型会自行决定是否调用工具还是直接回答. 如果指定了后者时, 则代表模型必然调用工具.
{
"functions": [
{
"name": "_OutputFormatter",
"description": "Output formatter. Should always be used to format your response to the user.",
"parameters": {
"type": "object",
"properties": {
"output": {
"description": "The input to the numexpr.evaluate() function.",
"type": "object",
"properties": {
"reasoning": {
"description": "The reasoning behind the code expression, including how context is included, if applicable.",
"type": "string"
},
"code": {
"description": "The simple code expression to execute by numexpr.evaluate().",
"type": "string"
}
},
"required": [
"reasoning",
"code"
]
}
},
"required": [
"output"
]
}
}
],
"function_call": {
"name": "_OutputFormatter"
}
}
验证:
# template | chat_llm.bind(...)
middle_result = (runnable.first | runnable.middle[0]).invoke({"text": "1+1"})
# AIMessage(
# content='',
# additional_kwargs={
# 'function_call': {
# 'arguments': '{"output":{"reasoning":"The user input is a simple addition operation.","code":"1+1"}}',
# 'name': '_OutputFormatter'
# }
# },
# response_metadata={
# 'token_usage': {
# 'completion_tokens': 21, 'prompt_tokens': 122, 'total_tokens': 143
# },
# 'model_name': 'gpt-3.5-turbo',
# 'system_fingerprint': None,
# 'finish_reason': 'stop',
# 'logprobs': None
# },
# id='run-3d02b918-73ea-4c3b-bce7-ae27227498a8-0',
# usage_metadata={'input_tokens': 122, 'output_tokens': 21, 'total_tokens': 143}
# )
# runnbale.last 就是 output_parser
runnable.last.invoke(middle_result)
# ExecuteCode(reasoning='The user input is a simple addition operation.', code='1+1')
例子 9: tool call: AIMessage/FunctionMessage/ToolMessage
参考这两篇 https://python.langchain.com/v0.2/docs/how_to/tool_calling/, https://python.langchain.com/v0.2/docs/how_to/tool_results_pass_to_model/
FunctionMessage/ToolMessage 代表的是工具调用的结果
from langchain_core.tools import tool
@tool
def add(a: int, b: int) -> int:
"""Adds a and b."""
return a + b
@tool
def multiply(a: int, b: int) -> int:
"""Multiplies a and b."""
return a * b
tools = [add, multiply]
from langchain_core.pydantic_v1 import BaseModel, Field
# Note that the docstrings here are crucial, as they will be passed along
# to the model along with the class name.
class Add(BaseModel):
"""Add two integers together."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
class Multiply(BaseModel):
"""Multiply two integers together."""
a: int = Field(..., description="First integer")
b: int = Field(..., description="Second integer")
tools = [Add, Multiply]
import os
from langchain_openai import ChatOpenAI
llm = ChatOpenAI()
llm_with_tools = llm.bind_tools(tools)
query = "What is 3 * 12?"
message = llm_with_tools.invoke(query) # message: AIMessage
message.__fields__
# {'content': ModelField(name='content', type=Union[str, List[Union[str, Dict]]], required=True),
# 'additional_kwargs': ModelField(name='additional_kwargs', type=dict, required=False, default_factory='<function dict>'),
# 'response_metadata': ModelField(name='response_metadata', type=dict, required=False, default_factory='<function dict>'),
# 'type': ModelField(name='type', type=Literal['ai'], required=False, default='ai'),
# 'name': ModelField(name='name', type=Optional[str], required=False, default=None),
# 'id': ModelField(name='id', type=Optional[str], required=False, default=None),
# 'example': ModelField(name='example', type=bool, required=False, default=False),
# 'tool_calls': ModelField(name='tool_calls', type=List[ToolCall], required=False, default=[]),
# 'invalid_tool_calls': ModelField(name='invalid_tool_calls', type=List[InvalidToolCall], required=False, default=[]),
# 'usage_metadata': ModelField(name='usage_metadata', type=Optional[UsageMetadata], required=False, default=None)}
message
# content, additional_kwargs, response_metadata 应该是原本的大模型提供商的返回字段
# tool_calls 和 usage_metadata 是加工为 AIMessage 时自动从 additional_kwargs, response_metadata 抽取的
# AIMessage(
# content='',
# additional_kwargs={
# 'tool_calls': [
# {
# 'id': 'call_20240715163333eab6ec8917a24963a9de8bac85ff5580',
# 'function': {'arguments': '{"a":3,"b":12}', 'name': 'Multiply'},
# 'type': 'function',
# 'index': 0
# }
# ]
# },
# response_metadata={'token_usage': {'completion_tokens': 17, 'prompt_tokens': 237, 'total_tokens': 254}, 'model_name': 'glm-4', 'system_fingerprint': None, 'finish_reason': 'tool_calls', 'logprobs': None},
# id='run-9c045ba1-9eed-4038-b98c-a07c483590c1-0',
# tool_calls=[
# {
# 'name': 'Multiply',
# 'args': {'a': 3, 'b': 12},
# 'id': 'call_20240715163333eab6ec8917a24963a9de8bac85ff5580'
# }
# ],
# usage_metadata={'input_tokens': 237, 'output_tokens': 17, 'total_tokens': 254}
# )
tool_results = []
for tool_call in message.tool_calls:
selected_tool = {"add": add, "multiply": multiply}[tool_call["name"].lower()]
tool_output = selected_tool.invoke(tool_call["args"])
tool_results.append(ToolMessage(tool_output, tool_call_id=tool_call["id"]))
tool_results[0].__fields__
# {'content': ModelField(name='content', type=Union[str, List[Union[str, Dict]]], required=True),
# 'additional_kwargs': ModelField(name='additional_kwargs', type=dict, required=False, default_factory='<function dict>'),
# 'response_metadata': ModelField(name='response_metadata', type=dict, required=False, default_factory='<function dict>'),
# 'type': ModelField(name='type', type=Literal['tool'], required=False, default='tool'),
# 'name': ModelField(name='name', type=Optional[str], required=False, default=None),
# 'id': ModelField(name='id', type=Optional[str], required=False, default=None),
# 'tool_call_id': ModelField(name='tool_call_id', type=str, required=True)}
tool_results[0]
# ToolMessage(
# content='36',
# tool_call_id='call_20240715163333eab6ec8917a24963a9de8bac85ff5580'
# )
Cookbook
ConversationalRetrievalChain (TODO)
Agents
不同的 Agent 一般只是 prompt 和 output parser 不太相同, 而默认的 prompt 一般外挂在 langchain hub, 默认的 output parser 位于 langchain 代码库内
structured_chat vs ReAct: ReAct 的工具都只能接收字符串作为输入, 而 structured_chat 的工具可以接收多个参数作为输入, 区别主要是
- prompt 不同
- output parser 不同:
structured_chat是JSONAgentOutputParser,ReAct是ReActSingleInputOutputParser - tool 的调用格式不同 (
tool.run(tool_input=tool_input)):structured_chat的输入参数tool_input可以是一个字典, 而ReAct所使用的工具只能是字符串# 可适用于 structured_chat @langchain.tools.tool def search(q: str, p: str) -> str: """Look up things online.""" return q + p search.run(tool_input={"q": "1", "p": "2"}) # 既可适用于 structured_chat, 又可适用于 ReAct @langchain.tools.tool def search(q: str) -> str: """Look up things online.""" return q search.run(tool_input="1") search.run(tool_input={"q": "1"})
def create_structured_chat_agent(
llm: BaseLanguageModel, tools: Sequence[BaseTool], prompt: ChatPromptTemplate
) -> Runnable:
prompt = prompt.partial(
tools=render_text_description_and_args(list(tools)), # 注意这里还包含args的描述, 即: tool.name, tool.description, tool.args
tool_names=", ".join([t.name for t in tools]),
)
llm_with_stop = llm.bind(stop=["Observation"])
agent = (
RunnablePassthrough.assign(
agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),
)
| prompt
| llm_with_stop
| JSONAgentOutputParser() # 这里用的是 JSONAgentOutputParser, 用于解析 json 字符串, 从而拿到 action (string) 和 action_input (dict)
)
return agent
def create_react_agent(llm, tools, prompt):
prompt = prompt.partial(
tools=render_text_description(list(tools)),
tool_names=", ".join([t.name for t in tools]),
)
llm_with_stop = llm.bind(stop=["\nObservation"])
agent = (
RunnablePassthrough.assign(agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),)
| prompt
| llm_with_stop
| ReActSingleInputOutputParser() # 这里用的是 ReActSingleInputOutputParser, 用于提取 Action: 和 Action Input: 后面的内容
)
return agent
Concept
Runnable vs Chain
推荐用 LCEL 而非继承自 Chain 的原因
from langchain.chains.llm import LLMChain
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import StrOutputParser
prompt = ChatPromptTemplate.from_messages([
("system", "You are world class technical documentation writer."),
("user", "{input}")
])
llm = ChatOpenAI()
output_parser = StrOutputParser()
# 真流式: 新式 Chain
lcel_chain = prompt | llm | output_parser
for i in lcel_chain.stream({"input": "count from 1 to 100"}):
print(i)
# 伪流式: 旧式 Chain
old_chain = LLMChain(prompt=prompt, llm=llm, output_parser=output_parser)
for i in old_chain.stream({"input": "count from 1 to 100"}):
print(i)
Chain 分为旧式的和新式的:
- 旧式的
XXChain从形式上是通过继承的方式来处理的, 其invoke是按照次序依次调用内部的 runnables 的与 invoke 相关的方法来实现的 - 新式的
create_xx_chain从形式上是通过Runnable通过连接符|得到的, 其invoke方法存粹是用由 LCEL 本身提供的
旧式 Chain 的使用
from langchain.chains.combine_documents.stuff import StuffDocumentsChain
from langchain.chains import StuffDocumentsChain, LLMChain
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import OpenAI
document_prompt = PromptTemplate(input_variables=["page_content"], template="{page_content}")
document_variable_name = "context"
llm = OpenAI()
prompt = PromptTemplate.from_template("Summarize this content: {context}")
llm_chain = LLMChain(llm=llm, prompt=prompt)
# 旧式 Chain: 采用继承的方式串接各个 runnable 组件, 继承关系如下
# StuffDocumentsChain -> BaseCombineDocumentsChain -> Chain -> RunnableSerializable -> (Serializable, Runnable)
chain = StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt,
document_variable_name=document_variable_name
)
新式 Chain 的使用: TODO: 对齐旧式类
from langchain_community.chat_models import ChatOpenAI
from langchain_core.documents import Document
from langchain_core.prompts import ChatPromptTemplate
from langchain.chains.combine_documents import create_stuff_documents_chain
prompt = ChatPromptTemplate.from_messages(
[("system", "What are everyone's favorite colors:\\n\\n{context}")]
)
llm = ChatOpenAI(model_name="gpt-3.5-turbo")
# 新式 Chain: 直接用 | 以及 RunnableParallel, RunnablePassThrough 等串接各个 runnable 组件, 内部实现大致如下
# (RunnablePassthrough.assign(**{DOCUMENTS_KEY: format_docs}).with_config(...) | prompt | llm | _output_parser).with_config(...)
chain = create_stuff_documents_chain(llm, prompt)
旧式 Chain 的实现
# 注意 Chain 本身在 Runnable 的基础上只实现了 invoke 和 ainvoke, 而沿用了 Runnable 的 stream 方法, 因此是伪流式的
# 所以使用继承 Chain 的方式, 如果要支持流式可能需要写很多额外代码
class LLMChain(Chain):
prompt: BasePromptTemplate
llm: Union[
Runnable[LanguageModelInput, str], Runnable[LanguageModelInput, BaseMessage]
]
output_key: str = "text"
output_parser: BaseLLMOutputParser = Field(default_factory=StrOutputParser)
return_final_only: bool = True
llm_kwargs: dict = Field(default_factory=dict)
def _call(...):
prompt = self.prompt.format_prompt(input)
generation = self.llm.generate_prompt(prompt)
result = self.output_parser.parse_result(generation)
return result
chain = LLMChain(prompt=prompt, llm=llm, output_parser=output_parser)
新式 Chain 的实现
chain = prompt | llm | output_parser
Memory (For Legacy Chain vs For LCEL)
官方文档中提到大部分出于 Beta 状态, 不是很理解: https://python.langchain.com/docs/modules/memory/
Most of memory-related functionality in LangChain is marked as beta. This is for two reasons:
- Most functionality (with some exceptions, see below) are not production ready
- Most functionality (with some exceptions, see below) work with Legacy chains, not the newer LCEL syntax.
- 新类似乎是这里:
BaseChatMessageHistory, 一般用于RunnableWithMessageHistory, 见这个例子 和这个例子. 而RunnableWithMessageHistory接收的参数之一是get_session_history, 其类型是Callable[..., BaseChatMessageHistory], 而BaseChatMessageHistory的子类见这里# 与 LCEL 兼容指的是这种用法: 使用 RunnableWithMessageHistory 包住 runnable 和 BaseChatMessageHistory from langchain_community.chat_message_histories import ChatMessageHistory # from langchain_community.chat_message_histories import RedisChatMessageHistory from langchain_core.runnables.history import RunnableWithMessageHistory message_history = ChatMessageHistory() # 新 memory, 主要是包含 messages 属性以及 add_message 方法 runnable_with_chat_history = RunnableWithMessageHistory( runnable, lambda session_id: message_history, # lambda session_id: RedisChatMessageHistory(session_id, url=REDIS_URL, ttl=600), # 设置失效时间为 600 秒 input_messages_key="input", history_messages_key="chat_history", ) - 旧类似乎是这里:
ConversationBufferMemory,ConversationBufferWindowMemory, 所有的子类及用法见这里# 旧的 Memory 与旧的 Chain 兼容, 指的是这种用法: from langchain_openai import OpenAI from langchain.chains import ConversationChain # 旧 Chian conversation_with_summary = ConversationChain( llm=OpenAI(temperature=0), memory=ConversationBufferWindowMemory(k=2), # 旧 memory, 主要实现了 load_memory_variables 和 save_context 方法 verbose=True ) conversation_with_summary.predict(input="Hi, what's up?")
Tool, Agent, AgentExecutor
Agent 也分为新式的与旧式的 (旧式的用法 LangChain 计划于 0.2.0 版本弃用)
- 旧式的: 使用
Agent.from_llm_and_tools, 这种用法似乎已经在官方文档上找不到例子了:# langchain/agents/react/base.py # 以下均被标记为: deprecated("0.1.0", removal="0.2.0") class ReActDocstoreAgent(Agent): ... class DocstoreExplorer: ... class ReActTextWorldAgent(ReActDocstoreAgent): ... class ReActChain(AgentExecutor): ... # 注意 ReActChain 将被弃用, 但 AgentExecutor 依然会是主要 API - 新式的: 使用
create_*_agent构造 LCEL 链, 然后用AgentExecutor包裹一层, 以下例子参考自 https://python.langchain.com/docs/modules/agents/agent_types/reactfrom langchain.agents import AgentExecutor, create_react_agent agent = create_react_agent(llm, tools, prompt) agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True) agent_executor.invoke({"input": "what is LangChain?"})而
create_react_agent的实质是:def create_react_agent(llm, tools, prompt): prompt = prompt.partial( tools=render_text_description(list(tools)), tool_names=", ".join([t.name for t in tools]), ) llm_with_stop = llm.bind(stop=["\nObservation"]) agent = ( RunnablePassthrough.assign(agent_scratchpad=lambda x: format_log_to_str(x["intermediate_steps"]),) | prompt | llm_with_stop | ReActSingleInputOutputParser() ) return agent
新式的 Agent 实际上就是 LCEL 链, 与 Chain 没有区别, AgentExecutor (也是 LCEL) 会用 AgentRunnable (非 LCEL) 包裹 Agent
疑问: 为什么要包 AgentExecutor 这一层: https://python.langchain.com/docs/modules/agents/concepts#agentexecutor, AgentExecutor 大体上是如下
next_action = agent.get_action(...)
while next_action != AgentFinish:
observation = run(next_action)
next_action = agent.get_action(..., next_action, observation)
return next_action
Code
Utilities
ChatPromptTemplate 似乎没有很好的打印方式, 可以使用如下代码段
from langchain import hub
from langchain_core.utils.input import get_colored_text
def print_chat_prompt_template(chat_prompt_template):
for message in chat_prompt_template.messages:
message_type = message.__class__.__name__
print(get_colored_text(message_type, "green"))
if message_type == "MessagesPlaceholder":
print(message)
else:
print(message.prompt.template)
structured_chat_prompt = hub.pull("hwchase17/structured-chat-agent")
print_chat_prompt_template(structured_chat_prompt)
Custom Components
调试时有可能需要制造一些假的组件
Custom LLM
https://python.langchain.com/docs/modules/model_io/llms/custom_llm
官方也提供了一个 FakeListLLM: https://github.com/langchain-ai/langchain/blob/master/libs/community/langchain_community/llms/fake.py
from typing import Any, List, Mapping, Optional, Iterator
from langchain.callbacks.manager import CallbackManagerForLLMRun
from langchain_core.outputs import GenerationChunk
from langchain.llms.base import LLM
class FixedReturnLLM(LLM):
fixed_return_string: str
@property
def _llm_type(self) -> str:
return "custom"
def _call(
self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> str:
return self.fixed_return_string
def _stream(self,
prompt: str,
stop: Optional[List[str]] = None,
run_manager: Optional[CallbackManagerForLLMRun] = None,
**kwargs: Any,
) -> Iterator[GenerationChunk]:
for s in self.fixed_return_string:
yield GenerationChunk(text=s)
@property
def _identifying_params(self) -> Mapping[str, Any]:
"""Get the identifying parameters."""
return {"fixed_return_string": self.fixed_return_string,}
fake_llm = FixedReturnLLM(fixed_return_string="Final Answer: yyy")
fake_llm.invoke("x") # "Final Answer: yyy"
list(fake_llm.stream("x")) # ['F', 'i', 'n', 'a', 'l', ' ', 'A', 'n', 's', 'w', 'e', 'r', ':', ' ', 'y', 'y', 'y']
Custom Retriever
https://python.langchain.com/docs/modules/data_connection/retrievers/#custom-retriever
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
from langchain.tools.retriever import create_retriever_tool
class FixedReturnRetriever(BaseRetriever):
fixed_return_documents: List[str]
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=doc) for doc in self.fixed_return_documents]
fake_retriever = FixedReturnRetriever(fixed_return_documents=["foobar"])
fake_retriever.get_relevant_documents("bar") # [Document(page_content='foobar')]
fake_retriever_tool = create_retriever_tool(
fake_retriever,
"fake tool",
"This is fake tool's description",
)
fake_tools = [fake_retriever_tool]
Agent
TODO: 参考下文 LangSmith 里的例子
from langchain.agents import AgentExecutor, create_react_agent
from langchain import hub
prompt = hub.pull("hwchase17/react")
fake_agent = create_react_agent(fake_llm, fake_tools, prompt)
fake_agent_executor = AgentExecutor(agent=fake_agent, tools=fake_tools, verbose=True)
fake_agent_executor.invoke({"input": "x"}) # {'input': 'x', 'output': 'xxx'}
# 控制台输出
# > Entering new AgentExecutor chain...
# Final Answer: xxx
# > Finished chain.
# 直接对 agent 调用
fake_agent.invoke({"input": "x", "intermediate_steps": []}) # AgentFinish(return_values={'output': 'xxx'}, log='Final Answer: xxx')
Message
from langchain_core.messages.base import BaseMessage, BaseMessageChunk
# 以下都继承自 BaseMessage
from langchain_core.messages.ai import AIMessage, AIMessageChunk
from langchain_core.messages.chat import ChatMessage, ChatMessageChunk # 可以指定角色为任意字符串, 用的不多
from langchain_core.messages.function import FunctionMessage, FunctionMessageChunk # 代表用户自行调用函数后得到的结果
from langchain_core.messages.human import HumanMessage, HumanMessageChunk
from langchain_core.messages.system import SystemMessage, SystemMessageChunk
from langchain_core.messages.tool import ToolMessage, ToolMessageChunk # 代表用户自行调用工具后得到的结果
一般来说, 优先使用 AIMessage, HumanMessage, FunctionMessage, ToolMessage, SystemMessage. 例如:
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_core.messages import ChatMessage, AIMessage, HumanMessage
_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Translate user input into pirate speak",
),
MessagesPlaceholder("chat_history"),
("human", "{text}"),
]
)
_model = ChatOpenAI()
chain = _prompt | _model
input_1 = {
"chat_history": [
ChatMessage(content="hello", role="user"), # 注意对于openai来说这里必须设置为 "user", 而不能是 "human", 但是不同的模型可能不一样
ChatMessage(content="hello", role="assistant"),# 注意对于openai来说这里必须设置为 "assistant", 而不能是 "ai", 但是不同的模型可能不一样
],
"text": "Who are you"
}
input_2 = {
"chat_history": [
AIMessage(content="hello"), # 使用 AIMessage 可以避免上面使用 ChatMessage 必须设置对 role 的烦扰
HumanMessage(content="hello"),
],
"text": "Who are you"
}
input_3 = {
"chat_history": [
("human", "hello"), # 也可以简化用 tuple 来代替 message
("assistant", "hello")
],
"text": "Who are you"
}
res1: AIMessage = chain.invoke(input_1)
res2: AIMessage = chain.invoke(input_2)
res3: AIMessage = chain.invoke(input_3)
print("res1", res1.content)
print("res2", res2.content)
print("res3", res3.content)
Runnable (LCEL) (TODO)
本节内容作为 https://python.langchain.com/docs/expression_language/ 的补充与解释
# langchain_openai.chat_models.base.ChatOpenAI: public class
class ChatOpenAI(BaseChatModel):
def _stream(...): ...
def _generate(...): ...
async def _astream(...): ...
async def _agenerate(...): ...
class BaseChatModel(BaseLanguageModel[BaseMessage], ABC):
# invoke, ainvoke, stream, astream, generate, agenerate, generate_prompt, agenerate_prompt
class BaseLanguageModel(RunnableSerializable[LanguageModelInput, LanguageModelOutputVar], ABC):
# @abstractmethod: generate_prompt, agenerate_prompt
class RunnableSerializable(Serializable, Runnable[Input, Output]):
# configurable_fields, configurable_alternatives
class Runnable:
# 包含对外接口: invoke, ainvoke, stream, astream, batch, abatch, astream_log, astream_events
# 参考文档: https://python.langchain.com/docs/expression_language/interface
langchain_core 目录下所有以 "Runnable" 开头的类
Runnable
RunnableSerializable
RunnableSequence
RunnableParallel
RunnableLambda
RunnableEachBase
RunnableEach
RunnableBindingBase
RunnableBinding
RunnableBranch
RunnableConfig # 仅仅类似一个字典, 不是 runnable
RunnableConfigurableFields
RunnableConfigurableAlternatives
RunnableWithFallbacks
RunnableWithMessageHistory
RunnablePassthrough
RunnableAssign
RunnablePick
RunnableRetry
RunnableAgent
RunnableMultiActionAgent
| Runnable方法名 | 返回类型(粗略) | 说明 | 文档链接 |
|---|---|---|---|
| assign | RunnableSerializable: (self | RunnableAssign) | 添加字段 | https://python.langchain.com/docs/expression_language/how_to/passthrough |
| pipe | RunnableSequence | ||
| pick | RunnableSerializable: (self | RunnablePick) | ||
| bind | RunnableBinding | https://python.langchain.com/docs/expression_language/how_to/binding | |
| with_config, configurable_fields, configurable_alternatives | RunnableBinding | https://python.langchain.com/docs/expression_language/how_to/configure | |
| with_listeners | RunnableBinding | 用于 RunnableWithMessageHistory | https://python.langchain.com/docs/expression_language/how_to/message_history |
| with_types | RunnableBinding | ||
| with_retry | RunnableRetry | ||
| map | RunnableEach | ||
| with_fallbacks | RunnableWithFallbacks |
RunnableBranch 看起来是需要直接使用其构造函数的, 参考: https://python.langchain.com/docs/expression_language/how_to/routing
Runnable.invoke
class Runnable:
@abstractmethod
def invoke(self, input: Input, config: Optional[RunnableConfig] = None) -> Output: ...
Runnable.stream
疑问: LCEL 组合的时候, stream 的逻辑是什么? 以 prompt | llm | output_parser 为例, 中间的 llm 支持 stream (默认实现是用 invoke 来做的, 具体类会覆盖这个默认实现), 但是 prompt 和 output_parser 一般不支持, 看起来 llm 的后续环节也只能是等待, 如果中间有多个 stream 的体感不明显. 另外更大的疑问是整个链条调用 stream 时的具体执行流是怎样的 (调用每个模块的 stream?)
from langchain_core.prompts import PromptTemplate
prompt = PromptTemplate.from_template("{text}")
prompt.__class__.stream is Runnable.stream # True, 但这个实现就只是 yield self.invoke(...)
Runnable.with_config, configurable_fields, configurable_alternatives
参考: https://python.langchain.com/docs/expression_language/how_to/configure
configurable_fields用于将 Runnable 的一些参数暴露给with_config或invoke调节configurable_alternatives用于将 Runnable 串接为 Chain 后, 将某个 Runnable 整个进行替换, 暴露给with_config或invoke调节
模板
# 必须先 configurable_fields 或 configurable_alternatives, 再使用 with_config
runnable = runnable.configurable_fields(...) # 不同的 runnable 有不同的可设置 key, key 不能乱配
runnable = runnable.configurable_alternatives(...) # 配置可以替换整个runnable为其他runnable
runnable.with_config(configurable={"foo": 0.9})
例子
from langchain.prompts import PromptTemplate
from langchain_core.runnables.configurable import ConfigurableField
runnable = PromptTemplate.from_template("This is history: {history}, This is content: {content}")
runnable = runnable.configurable_fields(template=ConfigurableField(id="custom_template")) # "template" in runnable.__fields__.keys()
runnable.with_config(configurable={"custom_template": "{history} {content}"}).invoke({"history": "1", "content": "2"})
三种在 invoke 时设置 config 的做法:
prompt = PromptTemplate.from_template("Tell me a joke about {topic}").configurable_alternatives(
ConfigurableField(id="prompt_choice"),
default_key="joke",
poem=PromptTemplate.from_template("Write a short poem about {topic}"),
)
prompt.with_config(config={"configurable": {"prompt_choice": "poem"}}).invoke({"topic": "book"})
prompt.with_config(configurable={"prompt_choice": "poem"}).invoke({"topic": "book"})
prompt.invoke({"topic": "book"}, config={"configurable": {"prompt_choice": "poem"}})
# prompt.invoke({"topic": "book"}, configurable= {"prompt_choice": "poem"}) # ERROR: 不能用 configurable={"prompt_choice": "poem"}
一个 Chain 的例子
也可以混合使用 configurable_fields 和 configurable_alternatives, 参考上面的文档即可
from langchain.prompts import PromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.runnables.configurable import ConfigurableField
runnable = PromptTemplate.from_template("This is history: {history}, This is content: {content}")
runnable2 = PromptTemplate.from_template("context: {context}")
params = {"history": "1", "content": "2"}
# 必须对每个 runnable 组件设置 configurable_fields, 并且 id 必须不同, 否则会冲突
runnable = runnable.configurable_fields(template=ConfigurableField(id="custom_template1"))
runnable2 = runnable2.configurable_fields(template=ConfigurableField(id="custom_template2"))
chain = (runnable | (lambda x: {"context": x.text}) | runnable2)
# 注意对 chain 本身设置 configurable_fields 只能设置 ['name', 'first', 'middle', 'last']
# chain.configurable_fields(template=ConfigurableField(id="custom_template")) # ERROR! only support: ['name', 'first', 'middle', 'last']
chain.with_config(
configurable={
"custom_template1": "custom_template1 {history} {content}",
"custom_template2": "custom_template2 {context}"
}
).invoke(params)
一个与 langserver 结合的例子
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
from langchain.tools.retriever import create_retriever_tool
from langchain_core.runnables.configurable import ConfigurableField
class CustomRetriever(BaseRetriever):
prefix: str = "retriever"
k: int = 4
method: str = "L2"
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=doc) for doc in [f"{self.prefix}: {query}-{self.k}-{self.method}"]]
fake_retriever = CustomRetriever()
configurable_fake_retriever = fake_retriever.configurable_fields(
prefix=ConfigurableField(id="retriever_prefix"),
k=ConfigurableField(id="retriever_k"),
method=ConfigurableField(id="retriever_method"),
)
# configurable_fake_retriever.invoke(input="bar")
from langchain.prompts import PromptTemplate
prompt = PromptTemplate.from_template("This is history: {history}, This is content: {content}")
configurable_prompt = prompt.configurable_alternatives(
ConfigurableField(id="prompt_choice"),
default_key="default",
kv=PromptTemplate.from_template("{history}: {content}"),
)
# configurable_prompt.invoke({"history": "h", "content": "c"})
chain = (configurable_prompt | configurable_fake_retriever)
# chain.invoke({"history": "h", "content": "c"})
# chain.invoke({"history": "h", "content": "c"}, config={
# "configurable": {
# "prompt_choice": "kv",
# "retriever_prefix": "this is retriever",
# "retriever_k": 20,
# "retriever_method": "COSINE",
# }
# })
# fake_retriever 的 k 参数在 chain.invoke 之后会被复原
使用 python ls_test.py 启动, 在 http://localhost:8000/chain/playground/ 页面可配置上面设定的配置项
# ls_test.py
from fastapi import FastAPI
from langchain.schema import BaseOutputParser
from langserve import add_routes
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
# chain 的定义如上, 此处略
add_routes(
app,
chain,
path="/chain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="localhost", port=8000)
RunnableBinding
例子1
from langchain_core.runnables import RunnableSerializable
from langchain_core.runnables.utils import Input, Output
class CustomRunnable(RunnableSerializable[Input, Output]):
def invoke(self, input, config=None, **kwargs):
return {
"input": input,
**kwargs
}
CustomRunnable().bind(b=2).invoke(1, a=2) # {"input": 1, "a": 2, "b": 2}
例子2
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
from langchain_core.runnables.configurable import ConfigurableField
class CustomRetriever(BaseRetriever):
k: int = 4
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun, k=None
) -> List[Document]:
k = self.k if k is None else k
return [Document(page_content=f"{query}-result_{i}") for i in range(k)]
CustomRetriever().bind(k=3).invoke("text")
RunnableConfig
继承自字典类型, TODO: 具体包含的 key
RunnableLambda
参考文档 https://python.langchain.com/docs/expression_language/how_to/functions
# RunnableLambda 实现的大略逻辑如下
class RunnableLambda(Runnable[Input, Output]):
def __init__(
self,
func: Union[
Callable[[Input], Output],
Callable[[Input], Iterator[Output]],
Callable[[Input, RunnableConfig], Output],
Callable[[Input, CallbackManagerForChainRun], Output],
Callable[[Input, CallbackManagerForChainRun, RunnableConfig], Output],
],
afunc = None,
name: Optional[str] = None,
) -> None:
...
def _invoke(
self,
input: Input,
run_manager: CallbackManagerForChainRun,
config: RunnableConfig,
**kwargs: Any,
) -> Output:
output = call_func_with_variable_args(
self.func, input, config, run_manager, **kwargs
)
return cast(Output, output)
例子
from langchain_core.runnables import RunnableLambda, RunnableConfig
def func1(x):
return x
def func2(x, config: RunnableConfig):
return x["num"] + config["configurable"]["total"]
RunnableLambda(func1).invoke({"num": 1}) # {'num': 1}
RunnableLambda(func2).invoke({"num": 1}, config={"configurable": {"total": 100}}) # 101
RunnableLambda(func2).invoke({"num": 1}, config={"configurable": {"total": 100}, "foo": 2}) # 也 OK: 101
备注: RunnableLambda 没有继承自 RunnableSerializable 因此没有 configurable_fields, configurable_alternatives 方法, 并且 with_config 方法也不能设置 configurable
RunnableParallel
在调用 RunnableParallel 的 invoke 方法时会自动触发并行, 实现原理大致如下(langchain 的原始实现也是用的线程池)
from concurrent.futures import ThreadPoolExecutor
from typing import Callable, Any, Dict
import time
class ParallelTasks:
def __init__(self, tasks: Dict[str, Callable[[Any], Any]]):
self.tasks = tasks
def invoke(self, input):
with ThreadPoolExecutor(3) as executor:
futures = [
executor.submit(
callable,
input
)
for key, callable in self.tasks.items()
]
output = {key: future.result() for key, future in zip(self.tasks, futures)}
return output
def task_a_fn(x: Dict[str, int]):
time.sleep(1)
return x["a"] + x["b"]
def task_b_fn(x: Dict[str, int]):
time.sleep(1)
return x["a"] - x["b"]
tasks = ParallelTasks(
{
"task_a": task_a_fn,
"task_b": task_b_fn,
}
)
start_time = time.time()
output = tasks.invoke({"a": 1, "b": 2})
end_time = time.time()
print(end_time - start_time) # 1.0025877952575684
print(output) # {'task_a': 3, 'task_b': -1}
Memory (For Legacy Chain)
TL;DR(TODO, 这里写的混乱, 需要重新写过): 所谓 Memory For Legacy Chain, 实际上是 langchain_core.memory.BaseMemory 的子类, 而其最主要的方法是, load_memory_variables 和 save_context:
class BaseMemory(Serializable, ABC):
@abstractmethod
def load_memory_variables(self, inputs: Dict[str, Any]) -> Dict[str, Any]:
"""Return key-value pairs given the text input to the chain."""
@abstractmethod
def save_context(self, inputs: Dict[str, Any], outputs: Dict[str, str]) -> None:
"""Save the context of this chain run to memory."""
它一般是作为一个 runnable 的属性, 因此 runnable 的 invoke 方法需要在期望的时刻调用 load_memory_variables 和 save_context, 然而这种用法的关键是需要将 memory 设置为 runnable 的属性
以这个例子为例: https://python.langchain.com/docs/modules/memory/types/buffer_window
from langchain.memory import ConversationBufferWindowMemory
from langchain_openai import OpenAI
from langchain.chains import ConversationChain
conversation_with_summary = ConversationChain(
llm=OpenAI(temperature=0),
# We set a low k=2, to only keep the last 2 interactions in memory
memory=ConversationBufferWindowMemory(k=2),
verbose=True
)
conversation_with_summary.predict(input="Hi, what's up?")
conversation_with_summary.predict(input="What's their issues?")
conversation_with_summary.predict(input="Is it going well?")
conversation_with_summary.predict(input="What's the solution?")
这里稍微展开一下 ConversationChain.predict 的逻辑: 首先 ConversationChain 应该是属于所谓的 lagacy chains, predict 方法应该也会在 langchain 的后续版本完全被 invoke 方法取代, 而 invoke 方法的主要执行流程为:
# ConversationChain -> LLMChain -> Chain
# 以下均为大体流程
input = {"input": "Hi, what's up?"}
def invoke(self, input):
inputs = self.prep_inputs(input) # Chain 中定义
outputs = self._call(inputs) # LLMChain 中定义
final_outputs: Dict[str, Any] = self.prep_outputs(inputs, outputs) # Chain 中定义
return final_outputs
def prep_inputs(self, inputs)
if self.memory is not None:
external_context = self.memory.load_memory_variables(inputs)
inputs = dict(inputs, **external_context)
return inputs
def prep_outputs(self, inputs, outputs):
if self.memory is not None:
self.memory.save_context(inputs, outputs)
# 严格地说, prep_outputs 还包含一个 return_only_outputs 的入参, 默认值为 False, 此参数可以在 invoke 的时候进行传递
return {**inputs, **outputs}
def _call(inputs):
prompts, stop = self.prep_prompts(input_list, run_manager=run_manager)
self.llm.xxx(...)
return self.create_outputs(...)
从上面可以看出, 只需要关注 load_memory_variables 和 save_context 方法即可 (因为调用来自于 Chain 这个父类)
Memory (For LCEL, TODO: 本节非常混乱, 后期整理)
例子参考前面的例子 7, 核心是 langchain_core.runnable.history.RunnableWithMessageHistory (一个在 langchain_core 中定义的 Runnable 的子类) 搭配 BaseChatMessageHistory (例子中是它的子类 RedisChatMessageHistory)
class BaseChatMessageHistory(ABC):
messages: List[BaseMessage] # 子类继承时也可以做成 @property
def add_message(self, message: BaseMessage) -> None: ...
def add_messages(self, messages: Sequence[BaseMessage]) -> None: ...
再看看 RunnableWithMessageHistory
GetSessionHistoryCallable = Callable[..., BaseChatMessageHistory]
class RunnableWithMessageHistory(RunnableBindingBase):
def __init__(
self,
runnable: Union[
Runnable[
Union[MessagesOrDictWithMessages],
Union[str, BaseMessage, MessagesOrDictWithMessages],
],
LanguageModelLike,
],
get_session_history: GetSessionHistoryCallable,
*,
input_messages_key: Optional[str] = None,
output_messages_key: Optional[str] = None,
history_messages_key: Optional[str] = None,
history_factory_config: Optional[Sequence[ConfigurableFieldSpec]] = None,
**kwargs: Any,
) -> None:
history_chain: Runnable = RunnableLambda(self._enter_history, self._aenter_history).with_config(run_name="load_history")
messages_key = history_messages_key or input_messages_key
if messages_key:
history_chain = RunnablePassthrough.assign(**{messages_key: history_chain}).with_config(run_name="insert_history")
bound = (history_chain | runnable.with_listeners(on_end=self._exit_history)).with_config(run_name="RunnableWithMessageHistory")
if history_factory_config:
_config_specs = history_factory_config
else:
# If not provided, then we'll use the default session_id field
_config_specs = [
ConfigurableFieldSpec(
id="session_id",
annotation=str,
name="Session ID",
description="Unique identifier for a session.",
default="",
is_shared=True,
),
]
super().__init__(
get_session_history=get_session_history,
input_messages_key=input_messages_key,
output_messages_key=output_messages_key,
bound=bound,
history_messages_key=history_messages_key,
history_factory_config=_config_specs,
**kwargs,
)
可以看出来, 实际上是在内部构造了 LCEL Chain, 以及增加了 ConfigurableFieldSpec
下面接着关注 invoke 方法, 先看下其父类 RunnableBindingBase
class RunnableBindingBase(RunnableSerializable[Input, Output]):
# 注意这个 _merge_configs 在后面起了关键作用
def _merge_configs(self, *configs: Optional[RunnableConfig]) -> RunnableConfig:
# 这个 merge_configs 也有一段逻辑, 对 metadata, tags, configurable, callbacks 做合并, 其中 callbacks 的合并逻辑稍显复杂
config = merge_configs(self.config, *configs)
# 一般是 runnable.with_listener 时才会加上 config_factories 参数
return merge_configs(config, *(f(config) for f in self.config_factories))
def invoke(
self,
input: Input,
config: Optional[RunnableConfig] = None,
**kwargs: Optional[Any],
) -> Output:
return self.bound.invoke(
input,
self._merge_configs(config),
**{**self.kwargs, **kwargs},
)
class Runnable(Generic[Input, Output], ABC):
# 注意 RunnableBinding (重载 with_listener) -> RunnableBindingBase -> Runnable
def with_listeners(
self,
*,
on_start: Optional[Listener] = None,
on_end: Optional[Listener] = None,
on_error: Optional[Listener] = None,
) -> Runnable[Input, Output]:
from langchain_core.tracers.root_listeners import RootListenersTracer
# RootListenersTracer 属于 callback, 在各处的触发方式为:
# >>> callback_manager = CallbackManager.configure(callbacks, ...)
# >>> callback_manager.on_*_start(...)
# >>> runnable.invoke(...)
# >>> callback_manager.on_*_end(...)
return RunnableBinding(
bound=self,
config_factories=[
lambda config: {
"callbacks": [
RootListenersTracer(
config=config,
on_start=on_start,
on_end=on_end,
on_error=on_error,
)
],
}
],
)
下面继续观察前置的 history_chain
class RunnableWithMessageHistory(RunnableBindingBase):
# 在 RunnableWithMessageHistory.invoke 被触发时, 也就是
# (history_chain | runnable.with_listeners(on_end=self._exit_history)).invoke(..., config=xxx)
# 被触发 invoke 前, 先会触发 _merge_configs
def _merge_configs(self, *configs: Optional[RunnableConfig]) -> RunnableConfig:
config = super()._merge_configs(*configs)
expected_keys = [field_spec.id for field_spec in self.history_factory_config]
configurable = config.get("configurable", {})
missing_keys = set(expected_keys) - set(configurable.keys())
if missing_keys:
example_input = {self.input_messages_key: "foo"}
example_configurable = {
missing_key: "[your-value-here]" for missing_key in missing_keys
}
example_config = {"configurable": example_configurable}
raise ValueError(
f"Missing keys {sorted(missing_keys)} in config['configurable'] "
f"Expected keys are {sorted(expected_keys)}."
f"When using via .invoke() or .stream(), pass in a config; "
f"e.g., chain.invoke({example_input}, {example_config})"
)
parameter_names = _get_parameter_names(self.get_session_history)
if len(expected_keys) == 1:
# If arity = 1, then invoke function by positional arguments
message_history = self.get_session_history(configurable[expected_keys[0]])
else:
# otherwise verify that names of keys patch and invoke by named arguments
if set(expected_keys) != set(parameter_names):
raise ValueError(
f"Expected keys {sorted(expected_keys)} do not match parameter "
f"names {sorted(parameter_names)} of get_session_history."
)
message_history = self.get_session_history(
**{key: configurable[key] for key in expected_keys}
)
config["configurable"]["message_history"] = message_history
return config
# 注意这个是包装原始 runnable 的前置 runnable
# history_chain: Runnable = RunnableLambda(self._enter_history, self._aenter_history).with_config(run_name="load_history")
# 条件触发: history_chain = RunnablePassthrough(history_chain)
# (history_chain | runnable.with_listeners(on_end=self._exit_history)).invoke(..., config=xxx)
def _enter_history(self, input: Any, config: RunnableConfig) -> List[BaseMessage]:
hist: BaseChatMessageHistory = config["configurable"]["message_history"] # 这个 "message_history" 来源于 self._merge_configs
messages = hist.messages.copy() # !!!!!! BaseChatMessageHistory.messages 用于此处
if not self.history_messages_key: # 注意在例 7 中, 不会进入这个分支
# return all messages
messages += self._get_input_messages(input)
return messages
def _get_input_messages(
self, input_val: Union[str, BaseMessage, Sequence[BaseMessage], dict]
) -> List[BaseMessage]:
from langchain_core.messages import BaseMessage
if isinstance(input_val, dict):
if self.input_messages_key:
key = self.input_messages_key
elif len(input_val) == 1:
key = list(input_val.keys())[0]
else:
key = "input"
input_val = input_val[key]
if isinstance(input_val, str):
from langchain_core.messages import HumanMessage
return [HumanMessage(content=input_val)]
elif isinstance(input_val, BaseMessage):
return [input_val]
elif isinstance(input_val, (list, tuple)):
return list(input_val)
else:
raise ValueError(
f"Expected str, BaseMessage, List[BaseMessage], or Tuple[BaseMessage]. "
f"Got {input_val}."
)
再观察 runnable.with_listeners(on_end=self._exit_history)
class RunnableWithMessageHistory(RunnableBindingBase):
def _exit_history(self, run: Run, config: RunnableConfig) -> None:
hist: BaseChatMessageHistory = config["configurable"]["message_history"]
# Get the input messages
inputs = load(run.inputs)
input_messages = self._get_input_messages(inputs) # 前面已看过这部分代码
# If historic messages were prepended to the input messages, remove them to
# avoid adding duplicate messages to history.
if not self.history_messages_key:
historic_messages = config["configurable"]["message_history"].messages
input_messages = input_messages[len(historic_messages) :]
# Get the output messages
output_val = load(run.outputs)
output_messages = self._get_output_messages(output_val) # 与前面的 self._get_input_messages 类似
hist.add_messages(input_messages + output_messages) # !!!!!! BaseChatMessageHistory.add_messages 用于此处
Agent, AgentExecutor, RunnableAgent, RunnableMultiActionAgent
TL;DR: AgentExecutor 的入参 agent 需要满足的条件是
result = agent.invoke(
{
"input": "xxx",
"intermediate_steps": [
(AgentAction(...), observation),
]
}
)
result: Union[AgentAction, AgentFinish, List[AgentAction]]
继承关系
# RunnableAgent 和 RunnableMultiActionAgent 会在 AgentExecutor 初始化时包裹 LCEL
RunnableAgent -> BaseSingleActionAgent -> BaseModel
RunnableMultiActionAgent -> BaseMultiActionAgent -> BaseModel
LLMSingleActionAgent -> BaseSingleActionAgent # 弃用
Agent -> BaseSingleActionAgent # 弃用, 因此不分析
AgentExecutor -> Chain
AgentExecutor 在初始化时对入参 agent 进行了一层包裹:
class AgentExecutor(Chain):
# 注意传入的 agent 参数被转换为了 RunnableAgent 或 RunnableMultiActionAgent
@root_validator(pre=True)
def validate_runnable_agent(cls, values: Dict) -> Dict:
"""Convert runnable to agent if passed in."""
agent = values["agent"]
if isinstance(agent, Runnable):
try:
output_type = agent.OutputType
except Exception as _:
multi_action = False
else:
multi_action = output_type == Union[List[AgentAction], AgentFinish]
if multi_action:
values["agent"] = RunnableMultiActionAgent(runnable=agent)
else:
values["agent"] = RunnableAgent(runnable=agent)
return values
TODO: 参考下文中的 LangSmith 为例
fake_agent_executor = AgentExecutor(
agent=agent,
tools=tools,
verbose=True, # 默认为 False
handle_parsing_errors=True # 默认为 False
)
TODO: remove This
# output_parser 主要关注 parse 方法, invoke 一般也会回落到 parse 方法
agent.last.invoke(" LangChain is likely a company or project, so the best approach would be to use a search tool to find more information.\nAction: langchain_search\nAction Input: LangChain")
# AgentAction(
# tool='langchain_search',
# tool_input='LangChain',
# log=' LangChain is likely a company or project, so the best approach would be to use a search tool to find more information.\nAction: langchain_search\nAction Input: LangChain'
# )
AgentExecutor 直接继承自 Chain, 按上一节分析, 只需要关注 prep_inputs, _call, prep_outputs 方法即可, 而此处没有用到 memory, 所以 prep_inputs 和 prep_outputs 相当于直接跳过, 因此只关注 AgentExecutor._call 方法即可
class AgentExecutor(Chain):
# _call 的完整源码如下:
def _call(
self,
inputs: Dict[str, str],
run_manager: Optional[CallbackManagerForChainRun] = None,
) -> Dict[str, Any]:
"""Run text through and get agent response."""
# Construct a mapping of tool name to tool for easy lookup
name_to_tool_map = {tool.name: tool for tool in self.tools}
# We construct a mapping from each tool to a color, used for logging.
color_mapping = get_color_mapping(
[tool.name for tool in self.tools], excluded_colors=["green", "red"]
)
intermediate_steps: List[Tuple[AgentAction, str]] = []
# Let's start tracking the number of iterations and time elapsed
iterations = 0
time_elapsed = 0.0
start_time = time.time()
# We now enter the agent loop (until it returns something).
while self._should_continue(iterations, time_elapsed):
next_step_output = self._take_next_step(
name_to_tool_map,
color_mapping,
inputs,
intermediate_steps,
run_manager=run_manager,
)
# next_step_output 的类型是 Union[AgentFinish, List[Tuple[AgentAction, str]]]
# 如果是后一种情况, 每个 tuple 的第 2 项是工具的输出内容
if isinstance(next_step_output, AgentFinish):
return self._return(
next_step_output, intermediate_steps, run_manager=run_manager
)
intermediate_steps.extend(next_step_output)
if len(next_step_output) == 1: # 此处含义不明!!! 为什么需要这个长度为 1 的判断, 遍历一遍只要遇到有 return_direct 的工具就返回不行吗?
next_step_action = next_step_output[0]
# See if tool should return directly
# 所有的 tool 都继承自 BaseTool, 包含一个 return_direct 字段 (默认是 False)
# 如果某个 tool 的 return_direct 字段设置为 True, 那么只要调用了这个工具就直接把 observation 返回
# tool_return 的类型是 Optional[AgentFinish]
tool_return = self._get_tool_return(next_step_action)
if tool_return is not None:
return self._return(
tool_return, intermediate_steps, run_manager=run_manager
)
iterations += 1
time_elapsed = time.time() - start_time
# 此处表示超时或达到最大迭代次数, self.early_stopping_method 默认为 "force", 行为是
# output = AgentFinish(return_values={"output": "Agent stopped due to max iterations."}, log="")
output = self.agent.return_stopped_response(
self.early_stopping_method, intermediate_steps, **inputs
)
# 这里主要是触发 run_manager.on_agent_finish, 以及将结果处理成 output.return_values.update("intermediate_steps": intermediate_steps)
# 备注: 是否包含 intermediate_steps 视 self.return_intermediate_steps True/False 决定
return self._return(output, intermediate_steps, run_manager=run_manager)
_take_next_step 的实际运作逻辑大体如下, 实际实现还包了几层内部函数: _iter_next_step, _consume_next_step
def _take_next_step(...) -> Union[AgentFinish, List[Tuple[AgentAction, str]]]:
# self.agent 可能是 RunnableAgent 或 RunnableMultiActionAgent, 见下面说明
output: Union[AgentFinish, AgentAction, List[AgentAction]] = self.agent.plan(intermediate_steps,**inputs)
actions: List[AgentAction]
if isinstance(output, AgentFinish):
return output
else:
if isinstance(output, AgentAction):
actions = [output]
else:
actions = output
result: List[Tuple(AgentAction, str)]
for agent_action in actions:
if agent_action.tool in name_to_tool_map:
tool = name_to_tool_map[agent_action.tool]
observation: str = tool.run(agent_action.tool_input, ...) # 调用 tool 的 run 方法
else:
observation = InvalidTool().run(
{
"requested_tool_name": agent_action.tool,
"available_tool_names": list(name_to_tool_map.keys()),
}, ...
)
result.append((agent_action, observation))
return result
self.agent.plan 是 RunnableAgent.plan 或 RunnableMultiActionAgent.plan, 去掉注释的源码如下 (本质上实现一模一样), 底层都是通过内部的 runnable.stream 方法来实现的, 而这个 runnable 就是前面提到的 AgentExecutor 构造方法的入参, 也即 create_*_agent 的返回结果.
class RunnableAgent(BaseSingleActionAgent):
def plan(self, intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Callbacks = None, **kwargs: Any,
) -> Union[AgentAction, AgentFinish]:
inputs = {**kwargs, **{"intermediate_steps": intermediate_steps}}
final_output: Any = None
for chunk in self.runnable.stream(inputs, config={"callbacks": callbacks}):
if final_output is None:
final_output = chunk
else:
final_output += chunk
return final_output
class RunnableMultiActionAgent(BaseMultiActionAgent):
def plan(self, intermediate_steps: List[Tuple[AgentAction, str]],
callbacks: Callbacks = None, **kwargs: Any,
) -> Union[List[AgentAction], AgentFinish]:
inputs = {**kwargs, **{"intermediate_steps": intermediate_steps}}
final_output: Any = None
for chunk in self.runnable.stream(inputs, config={"callbacks": callbacks}):
if final_output is None:
final_output = chunk
else:
final_output += chunk
return final_output
Callback (tracing, visibility, labeling, …)
开箱即用的: https://python.langchain.com/docs/integrations/callbacks
- Argilla: feedback 标注, 应该可完全私有化部署, langchain文档, 官网
- Comet: tracing, 似乎不可私有部署, langchain文档, 官网
- Confident
- Context
- Infino
- Label Studio
- LLMonitor
- PromptLayer
- SageMaker Tracking
- Streamlit
- Trubrics
模块介绍参考这里: https://python.langchain.com/docs/modules/callbacks/
class RetrieverManagerMixin:
def on_retriever_error(self, error: BaseException, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any: ...
def on_retriever_end(self, documents: Sequence[Document], *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any: ...
class LLMManagerMixin:
def on_llm_new_token(
self, token: str, *,
chunk: Optional[Union[GenerationChunk, ChatGenerationChunk]] = None,
run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,
) -> Any:
"""Run on new LLM token. Only available when streaming is enabled.
Args:
token (str): The new token.
chunk (GenerationChunk | ChatGenerationChunk): The new generated chunk,
containing content and other information.
"""
def on_llm_end(self, response: LLMResult, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:""
def on_llm_error(self, error: BaseException, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
class ChainManagerMixin:
def on_chain_end(self, outputs: Dict[str, Any], *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
def on_chain_error(self, error: BaseException, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
def on_agent_action(self, action: AgentAction, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
def on_agent_finish(self, finish: AgentFinish, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
class ToolManagerMixin:
def on_tool_end(self, output: str, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
def on_tool_error(self, error: BaseException, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any:
class CallbackManagerMixin:
def on_llm_start(self, serialized: Dict[str, Any], prompts: List[str], *, run_id: UUID, parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any,
) -> Any: ...
def on_chat_model_start(self, serialized: Dict[str, Any], messages: List[List[BaseMessage]], *, run_id: UUID, parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any,
) -> Any: ...
def on_retriever_start(self, serialized: Dict[str, Any], query: str, *, run_id: UUID, parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any,
) -> Any: ...
def on_chain_start(self, serialized: Dict[str, Any], inputs: Dict[str, Any], *, run_id: UUID, parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, **kwargs: Any,
) -> Any: ...
def on_tool_start(self, serialized: Dict[str, Any], input_str: str, *, run_id: UUID, parent_run_id: Optional[UUID] = None,
tags: Optional[List[str]] = None, metadata: Optional[Dict[str, Any]] = None, inputs: Optional[Dict[str, Any]] = None, **kwargs: Any,
) -> Any: ...
class RunManagerMixin:
def on_text(self, text: str, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any: ...
def on_retry(self, retry_state: RetryCallState, *, run_id: UUID, parent_run_id: Optional[UUID] = None, **kwargs: Any,) -> Any: ...
class BaseCallbackHandler(
LLMManagerMixin,
ChainManagerMixin,
ToolManagerMixin,
RetrieverManagerMixin,
CallbackManagerMixin,
RunManagerMixin,
):
raise_error: bool = False
run_inline: bool = False
@property
def ignore_llm(self) -> bool:
"""Whether to ignore LLM callbacks."""
return False
@property
def ignore_retry(self) -> bool:
"""Whether to ignore retry callbacks."""
return False
@property
def ignore_chain(self) -> bool:
"""Whether to ignore chain callbacks."""
return False
@property
def ignore_agent(self) -> bool:
"""Whether to ignore agent callbacks."""
return False
@property
def ignore_retriever(self) -> bool:
"""Whether to ignore retriever callbacks."""
return False
@property
def ignore_chat_model(self) -> bool:
"""Whether to ignore chat model callbacks."""
return False
class AsyncCallbackHandler(BaseCallbackHandler):
# 全部定义为 async 版, 类似这种
# async def on_agent_action(...): ...
目前共 18 个, 分类及触发位置大体如下:
- LLM (
langchain_core.language_models.chat_models.BaseChatModel,langchain_core.language_models.llms.BaseLLM)on_llm_starton_chat_model_starton_llm_endon_llm_erroron_llm_new_token: 适用于 stream, 触发于得到new_token之后, TODO
- Retriever (
langchain_core.retrievers.BaseRetriever):on_retriever_starton_retriever_endon_retriever_error
- Tool (
langchain_core.tools.BaseTool):on_tool_starton_tool_endon_tool_error
- Chain (主要位于这几处:
langchain_core.runnables.base.Runnable,langchain_core.runnables.base.RunnableSequence,langchain.chains.base.Chain,langchain.chains.llm.LLMChain,langchain.agents.agent_iterator.AgentExecutorIterator):on_chain_starton_chain_endon_chain_error
- AgentExecutor (
langchain.agents.agent.AgentExecutor):on_agent_action: 触发于 agent 确定了 action 之后, 具体调用 tool 之前on_agent_finish: 触发于 agent 确定了结果是 finish 之后, 将结果返回之前
- 其他:
on_text: 最重要的入口位于LLMChain.prep_prompts方法里, 但也有许多具体的类也触发了这个 callbackon_retry:
VectorStore
TL;DR
VectorStore 需要实现 创建, 增, 删, 查 这几个功能, 而 as_retriever 得到的 VectorStoreRetriever 继承自 BaseRetriever, 其能力完全来自于 VectorStore, 关于如何继承的细节参考下一节关于 Retriever 的描述
VectorStore 的重点在于数据的管理, 当然也包含查询, 而 Retriever 只关注于查询. 因此可以说 VectorStore 在逻辑上已经实现了 Retriever 的接口. 但作为大模型应用的开发人员来说, 有时候并不需要关心数据的管理, 而只关注检索, 例如使用搜索引擎检索内容, 使用者并不关心搜索服务提供方内部的数据存储细节.
以下是最主要的抽象接口
# langchain_core/vectorstores.py
class VectorStore(ABC):
# 主要接口
@property
def embedding(self): ... # embedding 模型
def add_documents(self, documnets: List[Document], ...): ... # aadd_documents
def delete(self, ids, ...): raise NotImplementedError # adelete
# search 方法会分发至 similarity_search 和 max_marginal_relevance_search 方法
def search(self, query: str, search_type: str, **kwargs) -> List[Document]: ... # asearch
@classmethod
def from_documents(...): ... # afrom_documents
# 位于 langchain_community/vectore_stores/*.py 里的 VectorStore 的子类一般很少会重载 as_retriever.
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
# kwargs 一般只能包含 search_type 和 search_kwargs
tags = kwargs.pop("tags", None) or []
tags.extend(self._get_retriever_tags())
return VectorStoreRetriever(vectorstore=self, **kwargs, tags=tags)
# 底层接口, 继承时必须实现
@abstractmethod
def add_text(self, texts, metadatas, **kwargs): ... # aadd_texts
@classmethod
@abstractmethod
def from_texts(cls, texts, embedding, metadatas, **kwargs): # afrom_texts
@abstractmethod
def similarity_search(self, query, k=4, **kwargs): ...
# 其他接口, 继承时可以不必实现
# 以下 3 个方法对应于 VectorStoreRetriever 中的 3 中 search_type
# "similarity", "similarity_score_threshold", "mmr"
def similarity_search_with_score(...): raise NotImplementedError # asimilarity_search_with_score
def similarity_search_with_relevance_scores(...): ... # asimilarity_search_with_relevance_scores
def max_marginal_relevance_search(...): raise NotImplementedError # amax_marginal_relevance_search
def similarity_search_by_vector(...): raise NotImplementedError # asimilarity_search_by_vector
...
# 注意: search_type 和 search_kwargs 写在类属性里而不放在 _get_relevant_documents 的, 这样方便用 Runnable.with_config, configurable_fields
class VectorStoreRetriever(BaseRetriever):
vectorstore: VectorStore
search_type: str = "similarity"
search_kwargs: dict = Field(default_factory=dict)
allowed_search_types: ClassVar[Collection[str]] = ("similarity", "similarity_score_threshold", "mmr")
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun) -> List[Document]:
if self.search_type == "similarity":
docs = self.vectorstore.similarity_search(query, **self.search_kwargs)
elif self.search_type == "similarity_score_threshold":
docs_and_similarities = (
self.vectorstore.similarity_search_with_relevance_scores(
query, **self.search_kwargs
)
)
docs = [doc for doc, _ in docs_and_similarities]
elif self.search_type == "mmr":
docs = self.vectorstore.max_marginal_relevance_search(
query, **self.search_kwargs
)
else:
raise ValueError(f"search_type of {self.search_type} not allowed.")
return docs
# add_documents 不是 BaseRetriever 所需要的接口, 而是 VectorStoreRetriever 特有的接口
def add_documents(self, documents: List[Document], **kwargs: Any) -> List[str]:
"""Add documents to vectorstore."""
return self.vectorstore.add_documents(documents, **kwargs)
Retriever
TL;DR
目前版本继承自 BaseRetriever 的类, 只需要重载 _get_relevant_documents (如有必要, 重载 _aget_relevant_documents 方法) 即可, 而不能去重载 get_relevant_documents. 否则会在 __init_subclass__ 的检查中报警告. _get_relevant_documents 的重载方式为:
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun)-> List[Document]:
...
# TODO: 貌似没有什么不好的
# langchain_community/retrievers/weaviate_hybrid_search.py: WeaviateHybridSearchRetriever 用了这种方式
# 以下这种不推荐: 不太好配合 Runnable.with_config, configurable_fields 使用
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun, k, **kwargs)-> List[Document]:
...
继承 BaseRetriever 的例子:
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.runnables.configurable import ConfigurableField
class MyRetriever(BaseRetriever):
k: int = 2
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun, k=None, **kwargs):
k = self.k if k is None else k
return [f"{query} answer-{i}" for i in range(k)]
retriever = MyRetriever(k=3)
res0 = retriever.invoke("x", k=7) # 7 results
configurable_retriever = retriever.configurable_fields(k=ConfigurableField(id="default_k"))
res1 = configurable_retriever.bind(k=9).invoke("123", config={"configurable": {"default_k": 1}}) # 9 results
res2 = configurable_retriever.invoke("123", config={"configurable": {"default_k": 1}}) # 1 results
关于继承 VectorStore, BaseRetriever 的说明:
一般情况下: XYZVectorStore 需要支持 as_retriever 方法: VectorStore 中对 as_retriever 的默认实现是:
def as_retriever(self, **kwargs: Any) -> VectorStoreRetriever:
tags = kwargs.pop("tags", None) or []
tags.extend(self._get_retriever_tags())
return VectorStoreRetriever(vectorstore=self, **kwargs, tags=tags)
而 VectorStoreRetriever._get_relevant_documents 需要支持 3 类 search_type:
{
"similarity": vectorstore.similarity_search,
"similarity_score_threshold": vectorstore.similarity_search_with_relevance_scores,
"mmr": vectorstore.max_marginal_relevance_search
}
然而, 正如前面所述, XYZVectorStore 不必实现上面的这 3 个接口 (只需要实现 similarity_search 方法即可). 因此, 在 XYZVectorStore 没有全部实现这 3 个接口或者有其他 search_type 时, 有几个做法:
- 不实现
as_retriever方法 (重载为raise NotImplementedError), 而另外实现一个直接继承自BaseRetriever的类. 参考:langchain_coummnity/vector_stores/azuresearch.py的AzureSearch和AzureSearchVectorStoreRetriever - 重载
XYZVectorStore.as_retriever, 使它返回XYZVectorStoreRetriever; 并且重载XYZVectorStoreRetriever._get_relevant_documents. 参考:langchain_coummnity/vector_stores/redis/base.py的Redis和RedisVectorStoreRetriever - 另外, 如果只需要有查询接口, 可以不继承
VectorStore, 而直接继承BaseRetriever即可, 例如:langchain_coummnity/retrievers/weaviate_hybrid_search.py的WeaviateHybridSearchRetriever
BaseRetriever 的关键代码如下
class BaseRetriever(RunnableSerializable[RetrieverInput, RetrieverOutput], ABC):
# _new_arg_supported 和 _expects_other_args 会在子类继承时就会自动设定好
_new_arg_supported: bool = False
_expects_other_args: bool = False
tags: Optional[List[str]] = None
metadata: Optional[Dict[str, Any]] = None
def __init_subclass__(cls, **kwargs: Any) -> None:
super().__init_subclass__(**kwargs)
# Version upgrade for old retrievers that implemented the public methods directly.
if cls.get_relevant_documents != BaseRetriever.get_relevant_documents:
warnings.warn("Retrievers must implement abstract `_get_relevant_documents` method instead of `get_relevant_documents`", DeprecationWarning)
swap = cls.get_relevant_documents
cls.get_relevant_documents = BaseRetriever.get_relevant_documents
cls._get_relevant_documents = swap
if (hasattr(cls, "aget_relevant_documents") and cls.aget_relevant_documents != BaseRetriever.aget_relevant_documents):
warnings.warn(
"Retrievers must implement abstract `_aget_relevant_documents` method instead of `aget_relevant_documents`", DeprecationWarning)
aswap = cls.aget_relevant_documents
cls.aget_relevant_documents = BaseRetriever.aget_relevant_documents
cls._aget_relevant_documents = aswap
parameters = signature(cls._get_relevant_documents).parameters
cls._new_arg_supported = parameters.get("run_manager") is not None
cls._expects_other_args = (len(set(parameters.keys()) - {"self", "query", "run_manager"}) > 0)
# ainvoke, 在内部调用 get_relevant_documents
def invoke(
self, input: str, config: Optional[RunnableConfig] = None, **kwargs: Any
) -> List[Document]:
config = ensure_config(config)
return self.get_relevant_documents(
input,
callbacks=config.get("callbacks"),
tags=config.get("tags"),
metadata=config.get("metadata"),
run_name=config.get("run_name"),
**kwargs,
)
# aget_relevant_documents, 本质上就是 call hook + _get_relevant_documents
def get_relevant_documents(
self,
query: str,
*,
callbacks: Callbacks = None,
tags: Optional[List[str]] = None,
metadata: Optional[Dict[str, Any]] = None,
run_name: Optional[str] = None,
**kwargs: Any,
) -> List[Document]:
run_manager = callback_manager.on_retriever_start(...)
try:
_kwargs = kwargs if self._expects_other_args else {}
if self._new_arg_supported:
result = self._get_relevant_documents(query, run_manager=run_manager, **_kwargs)
else:
result = self._get_relevant_documents(query, **_kwargs)
except Exception as e:
run_manager.on_retriever_error(e)
raise e
else:
run_manager.on_retriever_end(result)
return result
# 继承自 BaseRetriever 的子类只要重载 _get_relevant_documents 即可
@abstractmethod
def _get_relevant_documents(self, query: str, *, run_manager: CallbackManagerForRetrieverRun)-> List[Document]: ... # _aget_relevant_documents
Tool
TODO:
- BaseTool, Tool, StructuredTool 之间的区别是什么
- 用装饰器,
create_retriever_tool, 以及继承以上三者, 怎样可以实现bind或configurable_fields
装饰函数
from langchain_core.tools import tool
@tool
def query_arxiv(query: str, k: int = 5) -> List[str]:
"""query arxiv data
Args:
query (str): query
k (int): nums of papers to query
Returns:
List[str]: paper title list
"""
return [f"{query}-result_{i}" for i in range(k)]
query_arxiv.invoke({"query": "abc", "k": 3})
# !!! Error!!!!
# configurable_query_arxiv = query_arxiv.configurable_fields(
# k=ConfigurableField(id="tool_k")
# )
retriever tool
from langchain_core.retrievers import BaseRetriever
from langchain_core.callbacks import CallbackManagerForRetrieverRun
from langchain_core.documents import Document
from typing import List
from langchain.tools.retriever import create_retriever_tool
from langchain_core.runnables.configurable import ConfigurableField
class CustomRetriever(BaseRetriever):
prefix: str = "retriever"
k: int = 4
method: str = "L2"
def _get_relevant_documents(
self, query: str, *, run_manager: CallbackManagerForRetrieverRun
) -> List[Document]:
return [Document(page_content=doc) for doc in [f"{self.prefix}: {query}-{self.k}-{self.method}"]]
fake_retriever = CustomRetriever()
configurable_fake_retriever = fake_retriever.configurable_fields(
prefix=ConfigurableField(id="retriever_prefix"),
k=ConfigurableField(id="retriever_k"),
method=ConfigurableField(id="retriever_method"),
)
configurable_fake_retriever.invoke(input="bar")
from langchain.tools.retriever import create_retriever_tool
# !!!! Error !!!!
# fake_retriever_tool = create_retriever_tool(configurable_fake_retriever, name="my retriever", description="desc")
fake_retriever_tool = create_retriever_tool(fake_retriever, name="my retriever", description="desc")
# !!!! Error !!!!
# fake_retriever_tool.configurable_fields(
# prefix=ConfigurableField(id="retriever_prefix")
# )
LangSmith
LangSmith 可以脱离 Langchain 使用, 但服务端代码 LangChain 公司没有开源 (客户端代码开源), 因此不能本地部署.
使用只需要简单设置两行即可
import os
os.environ["LANGCHAIN_TRACING_V2"]="true"
os.environ["LANGCHAIN_API_KEY"]="ls_xxx"
其原理是利用了 Callback 机制, 在 invoke 等方法被调用时自动添加 langchain_core.tracers.langchain.LangChainTracer, 而最终都会流向 langsmith.client.Client 的 create_run 与 update_run 方法上, 其中 create_run 都是在 on_*_start 时被触发, 而 update_run 都是在 on_*_end 和 on_*_error 时被触发, 注意 LangChainTracer 有 5 个 callback 没有实现, 分别是:
on_agent_action: TODO, 看下面的例子似乎应该有这个 hook ?on_agent_finishon_texton_retryon_llm_new_token
例子:
结合 https://python.langchain.com/docs/modules/agents/agent_types/react 和 https://python.langchain.com/docs/modules/agents/quick_start
import os
os.environ["OPENAI_API_KEY"] = "sk-xx"
os.environ["LANGCHAIN_TRACING_V2"] = "true"
os.environ["LANGCHAIN_API_KEY"] = "ls__yy"
os.environ["LANGCHAIN_PROJECT"] = "ReAct-test001"
from langchain.text_splitter import RecursiveCharacterTextSplitter
from langchain_community.document_loaders import WebBaseLoader
from langchain_community.vectorstores import FAISS
from langchain_openai import OpenAIEmbeddings
loader = WebBaseLoader("https://python.langchain.com/docs/get_started/introduction")
docs = loader.load()
documents = RecursiveCharacterTextSplitter(
chunk_size=1000, chunk_overlap=200
).split_documents(docs)
vector = FAISS.from_documents(documents, OpenAIEmbeddings())
retriever = vector.as_retriever()
from langchain.tools.retriever import create_retriever_tool
retriever_tool = create_retriever_tool(
retriever,
"langchain_search",
"Search for information about LangChain. For any questions about LangChain, you must use this tool!",
)
tools = [retriever_tool]
from langchain import hub
from langchain.agents import AgentExecutor, create_react_agent
from langchain_openai import OpenAI
prompt = hub.pull("hwchase17/react")
# Choose the LLM to use
llm = OpenAI() # !!! 这里不知道为啥用的不是 Chat 模型
# Construct the ReAct agent
agent = create_react_agent(llm, tools, prompt)
# Create an agent executor by passing in the agent and tools
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke({"input": "what is LangChain?"})
控制台输出 (文本)
> Entering new AgentExecutor chain...
LangChain is likely a company or project, so the best approach would be to use a search tool to find more information.
Action: langchain_search
Action Input: LangChainIntroduction | 🦜️🔗 Langchain
rely on a language model to reason (about how to answer based on provided context, what actions to take, etc.)This framework consists of several parts.LangChain Libraries: The Python and JavaScript libraries. Contains interfaces and integrations for a myriad of components, a basic run time for combining these components into chains and agents, and off-the-shelf implementations of chains and agents.LangChain Templates: A collection of easily deployable reference architectures for a wide variety of tasks.LangServe: A library for deploying LangChain chains as a REST API.LangSmith: A developer platform that lets you debug, test, evaluate, and monitor chains built on any LLM framework and seamlessly integrates with LangChain.Together, these products simplify the entire application lifecycle:Develop: Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.Productionize: Use LangSmith to inspect, test and monitor your chains, so that you can
up of several different packages.langchain-core: Base abstractions and LangChain Expression Language.langchain-community: Third party integrations.langchain: Chains, agents, and retrieval strategies that make up an application's cognitive architecture.Get startedHere’s how to install LangChain, set up your environment, and start building.We recommend following our Quickstart guide to familiarize yourself with the framework by building your first LangChain application.Read up on our Security best practices to make sure you're developing safely with LangChain.noteThese docs focus on the Python LangChain library. Head here for docs on the JavaScript LangChain library.LangChain Expression Language (LCEL)LCEL is a declarative way to compose chains. LCEL was designed from day 1 to support putting prototypes in production, with no code changes, from the simplest “prompt + LLM” chain to the most complex chains.Overview: LCEL and its benefitsInterface: The standard interface for LCEL
Write your applications in LangChain/LangChain.js. Hit the ground running using Templates for reference.Productionize: Use LangSmith to inspect, test and monitor your chains, so that you can constantly improve and deploy with confidence.Deploy: Turn any chain into an API with LangServe.LangChain LibrariesThe main value props of the LangChain packages are:Components: composable tools and integrations for working with language models. Components are modular and easy-to-use, whether you are using the rest of the LangChain framework or notOff-the-shelf chains: built-in assemblages of components for accomplishing higher-level tasksOff-the-shelf chains make it easy to get started. Components make it easy to customize existing chains and build new ones.The LangChain libraries themselves are made up of several different packages.langchain-core: Base abstractions and LangChain Expression Language.langchain-community: Third party integrations.langchain: Chains, agents, and retrieval strategies I now have a better understanding of what LangChain is and its various components and packages.
Final Answer: LangChain is a company that offers a framework for building and deploying applications using language models. It consists of several packages, including LangChain Libraries, LangChain Templates, LangServe, and LangSmith, which provide tools for developing, testing, and monitoring chains and agents. LangChain also offers an Expression Language (LCEL) for composing chains and third-party integrations for added functionality.
> Finished chain.
控制台输出 (带颜色)

LangSmith
分享链接: AgentExecutor, Retriever, 截图如下
LangServe & langchain-cli
LangServe
langserve 并不复杂, 目前 (2024/05/09) 应该也已基本稳定, 更新不多. 可以作为一个 FastAPI + React 的项目来学习, 下面仅介绍最基础的用法, 更复杂的用法直接参考 GitHub 仓库中的 README 以及 examples.
langserve 的 python 用法实际上主要是: add_routes 和 RemoteRunnable, 其中前者是服务端代码, 而后者是客户端代码. 如果需要更深入用, 服务端还可以使用 APIHandler, 但这里不介绍
Server: add_routes
# serve.py
from fastapi import FastAPI
from langserve import add_routes
from langchain_community.chat_models import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate, MessagesPlaceholder
_prompt = ChatPromptTemplate.from_messages(
[
(
"system",
"Translate user input into pirate speak",
),
MessagesPlaceholder("chat_history"),
("human", "{text}"),
]
)
_model = ChatOpenAI()
chain = _prompt | _model
app = FastAPI(
title="LangChain Server",
version="1.0",
description="A simple api server using Langchain's Runnable interfaces",
)
add_routes(
app,
chain,
path="/mychain",
)
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
正常使用 python serve.py 启动即可, add_routes 会增加一些路由:
http://127.0.0.1:8000/mychain/playground/http://127.0.0.1:8000/mychain/input_schema/http://127.0.0.1:8000/mychain/output_schema/http://127.0.0.1:8000/mychain/config_schema/http://127.0.0.1:8000/mychain/invoke/http://127.0.0.1:8000/mychain/batch/http://127.0.0.1:8000/mychain/stream/http://127.0.0.1:8000/mychain/stream_log/http://127.0.0.1:8000/mychain/stream_event/
add_routes 函数有一个参数 playground_type, 默认值为 "default", 此时前端的试用界面会是单次调用 (历史对话需要手动填充), 可以将其设置为 "chat", 前端界面会变成多轮对话形式 (可以参考pirate_speak_configurable), 可以使用 chat 模式的条件是 chain 的入参是一个字典, 且满足如下条件之一:
- (推荐) 只包含一个 key, 且值类型为
List[ChatMessage] - 包含两个 key, 其中一个 key 的值类型为
List[ChatMessage], 而另一个 key 的值类型为 string
备注: ChatMessage 实际上最好是用 AIMessage, HumanMessage, FunctionMessage, ToolMessage, SystemMessage 这些来替代
Client: RemoteRunnable
from langserve import RemoteRunnable
from langchain_core.messages import ChatMessage, AIMessage, HumanMessage
def use_langserve():
# OK
input_1 = {
"chat_history": [
ChatMessage(content="hello", role="user"),
ChatMessage(content="hello", role="assistant"),
],
"text": "Who are you"
}
# OK
input_2 = {
"chat_history": [
AIMessage(content="hello"),
HumanMessage(content="hello"),
],
"text": "Who are you"
}
# Error !!
input_3 = {
"chat_history": [
("human", "hello"),
("assistant", "hello")
],
"text": "Who are you"
}
runnable = RemoteRunnable("http://localhost:8000/mychain")
res: AIMessage = runnable.invoke(input_2)
return res
def use_requests():
import requests
data = {
"input": {
"chat_history": [
{
"content": "Hello",
"type": "ai",
},
{
"content": "Hello",
"type": "human",
},
],
"text": "Who are you"
}
}
res = requests.post(
"http://localhost:8000/mychain/invoke",
json=data,
)
res = res.json()
# res:
# {
# 'output': {
# 'content': "Arr matey, I be a friendly pirate assistant here to help ye with yer queries. What be ye needin' help with today?",
# 'additional_kwargs': {},
# 'response_metadata': {
# 'token_usage': {
# 'completion_tokens': 28,
# 'prompt_tokens': 30,
# 'total_tokens': 58
# },
# 'model_name': 'gpt-3.5-turbo',
# 'system_fingerprint': None,
# 'finish_reason': 'stop',
# 'logprobs': None
# },
# 'type': 'ai',
# 'name': None,
# 'id': 'run-597532ee-52a6-4dbc-91c0-a51941b926e8-0',
# 'example': False,
# 'tool_calls': [],
# 'invalid_tool_calls': []
# },
# 'metadata': {
# 'run_id': '288323b4-79ec-4235-80bc-8f7187b1acaa',
# 'feedback_tokens': []
# }
# }
return res
if __name__ == "__main__":
res1 = use_langserve()
print("langserve RemoteRunnable output\n", res1)
res2 = use_requests()
print("requests output\n", res2)
langchain-cli
安装方式: pip install langchain-cli
作为可执行脚本, langchain-cli 与 langchain 命令完全一样, cli/pyproject.toml 中有这种配置:
[tool.poetry.scripts]
langchain = "langchain_cli.cli:app"
langchain-cli = "langchain_cli.cli:app"
可以使用 langchain --help 查看使用方式, 包括以下命令:
# langchain app 主要是用于拉取 langchain 官方 Github 仓库里的 template
langchain app new ...
langchain app add ...
langchain app remove ...
langchain app serve ...
# langchain template 主要是用于创建 template
langchain template new ...
langchain template serve ...
langchain template list ...
langchain serve ... # 合并 langchain app serve 和 langchain template serve
langchain integration new ... # langchain 的开发人员工具, 在 libs/partners 目录下运行此命令, 以新增一个 partner 包, 例如 langchain-openai
这里简要描述一下要点, 后续章节继续深入
langchain template new的主要操作是复制 package_template, 并做一些 packagename 之类的替换, 注意这个 template 会随着pip install langchain-cli安装在本机的site-packages/langchain_cli目录下langchain app new类似, 复制 project_template, 并做一些替换, 这个 template 会随着pip install langchain-cli安装在本机的site-packages/langchain_cli目录下langchain app add的执行逻辑是先对app.firstpartyhq.com网址发请求告知需要拉取的模板, 但不一定需要成功, 猜测是 langchain 公司可以以此分析用户行为, 然后对 GitHub 发起请求拷贝 template (可以是 langchain 的官方 repo 或者是其他 repo). 具体拷贝的逻辑是:- 先使用 git clone/git pull 拷贝 (借助
GitPython包的相关方法) 至typer.get_app_dir("langchain")/git_repos/目录下 (在 linux 下通常是~/.config/langchain/git_repos目录), 目录结构类似于 ``` ~/.config/langchain/git_repos- langchain_ai_langchain_git_4fe265c3/ # 此为 git 管理的目录, 注意这里的 4fe265c3 是依据仓库名和分支名计算的, 所以每个仓库的每个分支会建一个缓存目录
- xx/ ```
- 然后再将上面的“缓存目录”拷贝至当前
langchain app的packages目录下 (注意不拷贝.git目录, 也就是只拷贝工作目录)
- 先使用 git clone/git pull 拷贝 (借助
langchain app remove的执行逻辑就是简单地删除langchain app的packages目录下相应的目录langchain serve/langchain template serve/langchain app serve则本质上都是借助langserve提供的langserve.add_routes
TODO: langchain-cli 的实现里比较重度依赖 typer 这个包, 是对 click 的封装, 似乎有很多包的命令行工具依赖于 click, 有空时可以仔细研究下这个包
langchain-cli: langchain app
langchain app 主要用于拉取 GitHub 上的模板, 按照 quickstart 说明, 使用
pip install -U langchain-cli
langchain app new my-app # 直接回车, 创建 my-app 目录
cd my-app
langchain app add pirate-speak # 在 packages 目录拉取 langchain/template/pirate-speak, 并使用 pip install -e packages/pirate-speak 安装
# 在 app/server.py 中做一些修改
# from pirate_speak.chain import chain as pirate_speak_chain
# add_routes(app, pirate_speak_chain, path="/pirate-speak")
export OPENAI_API_KEY=sk-...
langchain serve # 基本上就是假设脚本是 app/server.py
会得到这样类似的项目结构
.
├── Dockerfile
├── README.md
├── app
│ ├── __init__.py
│ └── server.py
├── packages
│ ├── README.md
│ └── pirate-speak
│ ├── LICENSE
│ ├── README.md
│ ├── pirate_speak
│ │ ├── __init__.py
│ │ └── chain.py
│ ├── poetry.lock
│ ├── pyproject.toml
│ └── tests
│ └── __init__.py
└── pyproject.toml
一个修改好的 serve.py 如下:
from fastapi import FastAPI
from fastapi.responses import RedirectResponse
from langserve import add_routes
from pirate_speak.chain import chain as pirate_speak_chain
app = FastAPI()
@app.get("/")
async def redirect_root_to_docs():
return RedirectResponse("/docs")
add_routes(app, pirate_speak_chain, path="/pirate-speak", playground_type="chat")
if __name__ == "__main__":
import uvicorn
uvicorn.run(app, host="0.0.0.0", port=8000)
本质上 langchain serve 在这个情形下基本等同于以下任意一条命令
langchain app serve
uvicorn app.server:app --host 127.0.0.1 --port 8000
langchain app add 详解
langchain app add --help 的输出如下
Usage: langchain app add [OPTIONS] [DEPENDENCIES]...
Adds the specified template to the current LangServe app.
e.g.: langchain app add extraction-openai-functions langchain app add
git+ssh://git@github.com/efriis/simple-pirate.git
╭─ Arguments ───────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ dependencies [DEPENDENCIES]... The dependency to add [default: None] │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
╭─ Options ─────────────────────────────────────────────────────────────────────────────────────────────────────────╮
│ --api-path TEXT API paths to add │
│ --project-dir PATH The project directory [default: None] │
│ --repo TEXT Install templates from a specific github repo instead │
│ --branch TEXT Install templates from a specific branch │
│ * --pip --no-pip Pip install the template(s) as editable dependencies [default: no-pip] │
│ [required] │
│ --help Show this message and exit. │
╰───────────────────────────────────────────────────────────────────────────────────────────────────────────────────╯
例子
langchain app new my-app
cd my-app
langchain app add pirate-speak
# 上面的命令等价于以下完整形式
# 等价方式1: 用 dependencies 直接确定
# --project-dir 用于指定整个的根目录, 由于已经切换到了 my-app 目录, 所以不用指定(或者说指定为了pwd)
# --api-path 用于指定本地安装的目录名, 例如可以将 pirate-speak 下载后重命名为 local-speak
# 但注意: --api-path 并没有修改 pyproject.toml, 也就是没有改 pip install -e 时的包名, 所以作用有限(不确定是 langchain 的 feature 还是 bug)
langchain app add \
git+https://github.com/langchain-ai/langchain.git@master#subdirectory=templates/pirate-speak \
--api-path pirate-speak \
--pip
# 等价方式2: 用 dependencies 和 --repo 以及 --branch 确定
langchain app add \
templates/pirate-speak \
--api-path pirate-speak \
--repo langchain-ai/langchain
--branch master \
--pip
# 备注: 在等价方式 1 中, 如果写做下面这种方式会导致缓存的 langchain_ai_langchain_git_4fe265c3 目录名的后面几位 hash 不一致, 会造成不必要的重复缓存
# 在等价方式及原始简写里, hash 的输入是:
# (1) 仓库URL: https://github.com/langchain-ai/langchain.git (2) 分支名: master
# 而改成 ssh 协议后, hash 的输入是:
# (1) 仓库URL: ssh://git@github.com/langchain-ai/langchain.git (2) 分支名: master
# git+ssh://git@github.com/langchain-ai/langchain.git@master#subdirectory=templates/pirate-speak \
langchain-cli: langchain template
langchain template 命令也是 langchain 的开发工具, 主要是在 langchain Github 仓库的 templates 下新建一个模板
lanchain template new my-template
cd my-template
pip install -e . # 必须
langchain serve
会得到这样类似的项目结构(参考: package_template)
.
└── my-template
├── LICENSE
├── README.md
├── my_template
│ ├── __init__.py
│ └── chain.py
├── pyproject.toml
└── tests
└── __init__.py
pip install -e .
TODO: 本小节内容在另一篇关于 python import system 的博客中再更深入地介绍处理办法 (目前那边写的也不完善)
为何需要使用 pip install -e . 将 my-template 进行安装? 原因是 langchain serve 的本质是执行类似这种 python 代码:
app = FastAPI()
package_root = get_package_root()
pyproject = package_root / "pyproject.toml"
package = get_langserve_export(pyproject)
mod = __import__(package["module"], fromlist=[package["attr"]])
chain = getattr(mod, package["attr"])
add_routes(
app,
chain,
config_keys=config_keys,
playground_type=playground_type,
)
uvicorn.run(
app, factory=True, reload=True,
port=port if port is not None else 8000,
host=host_str
)
# pyproject.toml 的相关内容
# [tool.langserve]
# export_module = "my_template"
# export_attr = "chain"
有没有办法避免 pip install -e .? 以下方案或许可性, 待验证
import importlib.util
import os
os.environ["OPENAI_API_KEY"] = "sk-xx"
module_path = "/path/to/my-template/my_template/chain.py"
module_name = "chain"
spec = importlib.util.spec_from_file_location(module_name, module_path)
module = importlib.util.module_from_spec(spec)
spec.loader.exec_module(module)
chain = getattr(module, 'chain')
LangGraph (TODO: 远未完成)
新开博客完成 …
Contributing
直接参考官方文档即可, 这里简要摘抄并做点解释
conda create -n langchain python=3.10
conda install pipx # 在当前虚拟环境安装
pipx install poetry # 全局可用
pipx ensurepath
poetry config virtualenvs.prefer-active-python true
# 假设要对 langchain-community 进行贡献
cd libs/community
poetry install --with lint,typing,test,test_integration
make test # pytest 测试
make format_diff # 格式化, 主要是 ruff, 不一定能完全自动化修复
make lint_diff # 静态检查, 主要是 mypy, 基本上需要手工修复发现的问题