(P1) ZeRO (deepspeed & pytorch fsdp)
动机、参考资料、涉及内容
参考资料
- ZeRo-Offload
- fairscale 的使用例子(推荐, 后续分析源码的目标): https://gist.github.com/aluo-x/85fda4f4f10895963d94000cf084514e
太长不看: 食用指南+DeepSpeed使用+Pytorch FSDP使用
原理简介【说人话版本】
- https://github.com/huggingface/transformers/issues/8771#issuecomment-758418429
- https://engineering.fb.com/2021/07/15/open-source/fsdp/: fairscale 博客
摘自 fairscale 博客
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i
forward pass for layer_i
discard full weights for layer_i
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i
backward pass for layer_i
discard full weights for layer_i
reduce-scatter gradients for layer_i
以下是个人拙见【不准确,待优化】
假设在 fp16 的情况下使用 Adam 进行训练, 模型参数量是 P, 假设总批量激活值的存储总共为 A, 假设现在希望做 N 卡并行, 显存主要包含几方面:
- 优化器状态: fp32 模型参数, Adam 对每个参数需要记录两个状态值
- fp16 模型参数
- fp16 模型梯度
ZeRO-1
每个 GPU 一部分优化器状态, 具体来说:
partial_optimizer_states = (partial_fp32_weights, partial_fp32_adam_betas_1, partial_fp32_adam_betas_2)
# 每个节点只需存储一份完整的 fp16 模型参数, 完整的 fp16 梯度, 一部分优化器状态, 全部的激活值
memory = [fp16_model, fp_16_grad, partial_optimizer_states, full_activations]
loss = fp16_model(input[local_rank*batch_size:(local_rank+1)*batch_size]) # 产生一些 activation
loss.backward() # fp16 模型梯度
# 以下有些模糊, 不确定
all_reduce(fp_16_grad, "MEAN") # 将梯度平均
update(partial_optimizer_states, fp_16_grad) # 更新自己维护的优化器状态
for rank in range(world_size):
if rank == local_rank:
cast_fp32_to_fp16(partial_fp32_weights, fp16_model, local_rank) # 更新一部分fp16模型参数, 简单的 fp32 cast to fp16
cast_fp32_to_fp16_and_broadcast_to(partial_fp32_weights) # 广播给其他进程自己的更新后参数
else:
receive_and_update(fp16_model, rank) # 接收其他进程广播的更新后参数
这样一来: 每个 GPU 所需要的显存量变为: 4*P+12*P/N + 2*A/N
ZeRO-2
在 ZeRO-1 的基础上, 每个 GPU 只保存一部分 fp16 的梯度, 具体来说:
partial_optimizer_states = (partial_fp32_weights, partial_fp32_adam_betas_1, partial_fp32_adam_betas_2)
# 每个节点只需存储一份完整的 fp16 模型参数, 一部分的 fp16 梯度, 一部分优化器状态, 全部的激活值
memory = [fp16_model, partial_fp_16_grad, partial_optimizer_states, full_activations]
loss = fp16_model(input[local_rank*batch_size:(local_rank+1)*batch_size]) # 产生一些 activation
# 将 backward 的过程一层一层地进行
dloss_dlayer = [loss]
# loss.backward()
for layer in model.layers[::-1]:
dloss_dlayer, layer_fp_16_grad = caculate_layer_fp16_grad(dloss_dlayer, layer)
reduce_scatter(layer_fp_16_grad, "MEAN") # 将这一层的梯度平均
partial_fp_16_grad.record(layer_fp_16_grad, layer) # 每个 GPU 只保留这一层一部分的梯度
update(partial_optimizer_states, partial_fp_16_grad) # 更新自己维护的优化器状态
for rank in range(world_size):
if rank == local_rank:
cast_fp32_to_fp16(partial_fp32_weights, fp16_model, local_rank) # 更新一部分fp16模型参数, 简单的 fp32 cast to fp16
cast_fp32_to_fp16_and_broadcast_to(partial_fp32_weights) # 广播给其他进程自己的更新后参数
else:
receive_and_update(fp16_model, rank) # 接收其他进程广播的更新后参数
这样一来: 每个 GPU 所需要的显存量变为: 2*P+14*P/N + 2*A/N
Zero-3
在 Zero-2 的基础上, 每个 GPU 只保留一部分权重参数, 原理是在 Zero-2 的基础上, 在前向或反向的操作时, 任何需要完整参数的操作首先触发一个 hook: 从其他的 N-1 个 GPU 上要过来所需要的参数再执行计算
这样一来: 每个 GPU 所需要的显存量变为: 16*P/N + 2*A/N
对比 DDP
在 DDP 的情况里, 每个 GPU 所需要的显存为: 16*P + 2*A/N, 因此如果参数量 P 过大时可能会超出如果单张 GPU 的最大显存, 然而在 ZeRO-3 的情况下, 每个 GPU 所需要的显存量为: 16*P/N + 2*A/N, 所以只要卡足够多, 总是能运行.
备注: 其实还有一些额外开销如下:
- 每张卡至少 batch size 为 1, activation 需要占一些显存
- 计算时实际上会再增加一些内存开销, 例如: 对于 Zero-3, 在执行一个算子时, 需要有充足的显存放下这个算子所需的完整模型参数
- 内存碎片问题
原理深入
参考资料:
食用指南
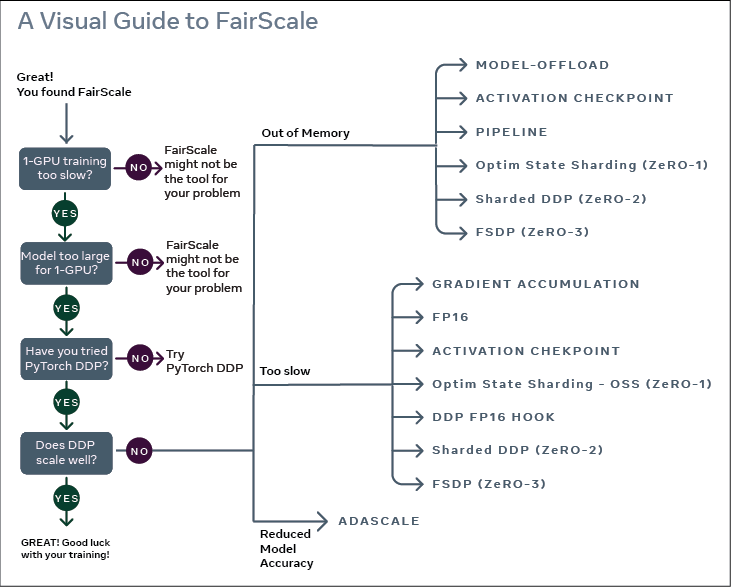
实验数据 (能训练多大的模型):
DeepSpeed 使用
本节主要介绍 deepspeed 的使用
Pytorch FSDP 使用
DDP vs FSDP
dist_init(rank, world_size)
model = myAwesomeModel().to(rank)
- model = DDP(model, device_ids=[rank])
+ model = FSDP(model, ...)
dataloader = mySuperFastDataloader()
loss_ln = myVeryRelevantLoss()
base_optimizer_arguments = { "lr": 1e-4}
optimizer = torch.optim.SGD(
params=model.parameters(),
**base_optimizer_arguments)
model.train()
for e in range(epochs):
for (data, target) in dataloader:
data, target = data.to(rank), target.to(rank)
# Train
model.zero_grad()
outputs = model(data)
loss = loss_fn(outputs, target)
loss.backward()
optimizer.step()
FairScale 源码分析
因为 fairscale 代码库比较简单, 因此适合仔细分析. 但使用上还是推荐用 Pytorch FSDP 或者 deepspeed.
Optimizer(OSS)
# fairscale/optim/oss.py
def _broadcast_object(
obj: Any, src_rank: int, group: object = dist.group.WORLD, dist_device: torch.device = torch.device("cpu")
) -> Any:
if dist.get_rank() == src_rank:
# Emit data
buffer = io.BytesIO()
torch.save(obj, buffer)
data = bytearray(buffer.getbuffer())
length_tensor = torch.LongTensor([len(data)]).to(dist_device)
data_send_tensor = torch.ByteTensor(data).to(dist_device)
dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)
dist.broadcast(data_send_tensor, src=src_rank, group=group, async_op=False)
else:
# Fetch from the source
length_tensor = torch.LongTensor([0]).to(dist_device)
dist.broadcast(length_tensor, src=src_rank, group=group, async_op=False)
data_recv_tensor = torch.empty([int(length_tensor.item())], dtype=torch.uint8, device=dist_device)
dist.broadcast(data_recv_tensor, src=src_rank, group=group, async_op=False)
buffer = io.BytesIO(data_recv_tensor.cpu().numpy())
obj = torch.load(buffer, map_location=dist_device)
return obj
本质上就是转为一种通用格式 byte, 然后发送和接受分别 ByteTensor, torch.load 和 torch.save 起了反序列化和序列化的作用.
import io
import torch
def seed(obj, dist_device):
buffer = io.BytesIO()
torch.save(obj, buffer)
data = bytearray(buffer.getbuffer())
length_tensor = torch.LongTensor([len(data)]).to(dist_device)
data_send_tensor = torch.ByteTensor(data).to(dist_device)
# 将 length_tensor 与 data_send_tensor 分别广播出去
return length_tensor, data_send_tensor
def recieve(length_tensor:torch.LongTensor, data_recv_tensor: torch.ByteTensor, dist_device):
buffer = io.BytesIO(data_recv_tensor.cpu().numpy()) # 这里要转成numpy, 有些神奇
obj = torch.load(buffer, map_location=dist_device)
return obj
obj = model.state_dict()
length_tensor, data_send_tensor = obj
new_obj = recieve(length_tensor, data_send_tensor, "cuda:0")
前置知识
optimizer = torch.optim.SGD(model.parameters(), lr=0.01)
# print(optimizer.param_groups)
# [
# {
# "params": List[nn.Parameters],
# "lr": 0.01,
# "momentum": 0,
# "dampening": 0,
# "weight_decay": 0,
# "nesterov": False
# }
# ]
接下来, 从下面这个写法入手
import torch
import torch.distributed as dist
import os
import torch.nn as nn
import torch.multiprocessing as mp
from fairscale.optim import OSS
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_1 = nn.Linear(28*28, 512)
self.linear_2 = nn.Linear(512, 512)
self.linear_3 = nn.Linear(512, 10)
def forward(self, x):
x = self.flatten(x)
return logits
def setup(rank, world_size):
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "12345"
dist.init_process_group("nccl", rank=rank, world_size=world_size)
def main(rank, world_size):
setup(rank, world_size):
model = NeuralNetwork().to(rank)
params = [
{"params": model.linear_1.parameters(), "lr": 0.1},
{"params": model.linear_2.parameters(), "lr": 0.2},
{"params": model.linear_3.parameters(), "lr": 0.3},
]
optimizer = OSS(params=params, optim=torch.optim.SGD, lr=0.001)
if __name__ == "__main__":
WORLD_SIZE = torch.cuda.device_count()
mp.spawn(
main,
args=(WORLD_SIZE,),
nprocs=WORLD_SIZE,
join=True
)
_partition_parameters 的分配逻辑很简单, 维护 WORLD_SIZE 长度的列表, 依次把每一个参数放入当前参数量最小的列表中
# 在每个进程上都存着完整的参数: _partition_parameters
optimizer._partition_parameters = [
[ # 代表 rank 0 的参数
{
"params": [linear_1.weight], # 注意此处存的是实际的参数, 在进程0上, 参数实际存储在 cuda:0 上
"lr": 0.1
},
{
"params": [],
"lr": 0.2
},
{
"params": [],
"lr": 0.3
}
],
[ # 代表 rank 1 的参数
{
"params": [linear_1.bias], # 注意此处存的是实际的参数, 在进程0上, 参数实际存储在 cuda:0 上
"lr": 0.1
},
{
"params": [linear_2.weight, linear_2.bias],
"lr": 0.2
},
{
"params": [linear_3.weight, linear_3.bias],
"lr": 0.3
}
]
]
rank 是进程, device 是参数所处的设备(GPU)
_partition_parameters:List,rank, parameter_group__per_device_params:Dict[torch.device, List[List[Parameter]]],device, rank, parameter__param_rank:Dict[Tensor, int],parameter, rank__local_params:Optional[List[Tensor]],__per_device_params中符合rank且梯度不为None的参数列表__param_to_index:Dict[int, int],id(parameter), idx
Pytorch FSDP (FairScale) vs DeepSpeed
本节主要解答两个疑问:
- 核心算法是否一致?
- deepspeed 大概还做了很多功能优化, pytorch 可能也做了一些优化, 目前从端到端效果看差距有多少?
一些实验数据
这篇 博客 指出即使在单卡的情况下, deepspeed 也能提供一些改善效果, 并且提到可以使用 24GB 单卡训练 t5-3b, 具体来说作者做了如下尝试
单卡不使用 deepspeed
# OOM!
export BS=1
CUDA_VISIBLE_DEVICES=0 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 [...]
单卡使用 deepspeed ZeRO-Offload
# OK
export BS=20
CUDA_VISIBLE_DEVICES=0 deepspeed --num_gpus=1 ./finetune_trainer.py \
--model_name_or_path t5-3b --n_train 60 --n_val 10 \
--per_device_eval_batch_size $BS --per_device_train_batch_size $BS \
--task translation_en_to_ro --fp16 --deepspeed ds_config_1gpu.json [...]
ds_config_1gpu.json 内容如下:
{
"fp16": {
"enabled": true,
"loss_scale": 0,
"loss_scale_window": 1000,
"hysteresis": 2,
"min_loss_scale": 1
},
"zero_optimization": {
"stage": 2,
"allgather_partitions": true,
"allgather_bucket_size": 2e8,
"reduce_scatter": true,
"reduce_bucket_size": 2e8,
"overlap_comm": true,
"contiguous_gradients": true,
"cpu_offload": true
},
"optimizer": {
"type": "Adam",
"params": {
"lr": 3e-5,
"betas": [ 0.9, 0.999 ],
"eps": 1e-8,
"weight_decay": 3e-7
}
},
"scheduler": {
"type": "WarmupLR",
"params": {
"warmup_min_lr": 0,
"warmup_max_lr": 3e-5,
"warmup_num_steps": 500
}
}
}