(Alpha) Pytorch Distributed Data Parallel
动机、参考资料、涉及内容
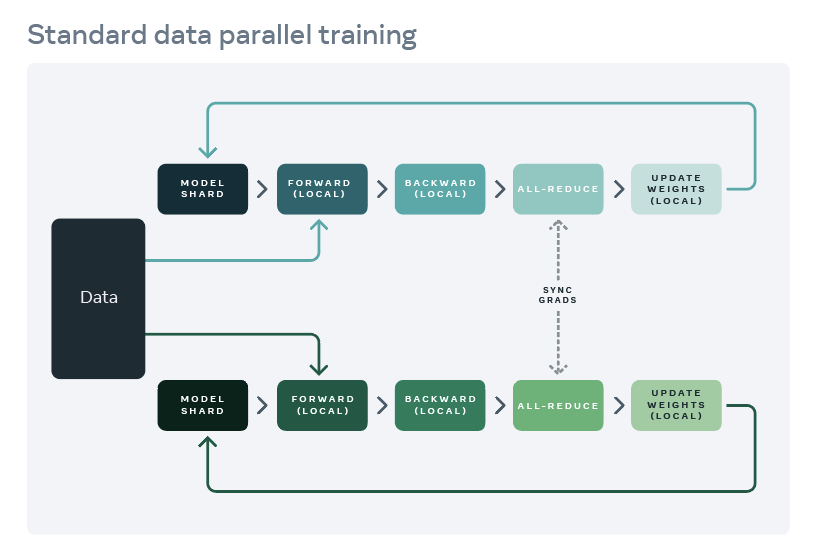
使用方法
相关的 API 内容参考: https://pytorch.org/docs/1.7.0/distributed.html
主要的使用方式有几种:
torch.multiprocessing.spawn: 不推荐torch.distributed.launch: 不推荐torch.distributed.run: 推荐
torch.multiprocessing.spawn
参考: https://pytorch.org/docs/1.7.1/notes/ddp.html
# test.py
import torch
import torch.distributed as dist
import torch.multiprocessing as mp
import torch.nn as nn
import torch.optim as optim
from torch.nn.parallel import DistributedDataParallel as DDP
def example(rank, world_size): # 注意: rank 参数会被自动传递, 由 nprocs 决定
# create default process group
dist.init_process_group("nccl", rank=rank, world_size=world_size)
# create local model
model = nn.Linear(10, 10).to(rank)
print("init weight:", "<rank {rank}>", model.weight[0, 0].item())
# construct DDP model
ddp_model = DDP(model, device_ids=[rank])
# define loss function and optimizer
loss_fn = nn.MSELoss()
optimizer = optim.SGD(ddp_model.parameters(), lr=1.)
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
print("weight grad 1:", "<rank {rank}>", model.weight.grad[0, 0].item())
# update parameters
optimizer.step()
print("weight update 1:", "<rank {rank}>", model.weight[0, 0].item())
optimizer.zero_grad()
# forward pass
outputs = ddp_model(torch.randn(20, 10).to(rank))
labels = torch.randn(20, 10).to(rank)
# backward pass
loss_fn(outputs, labels).backward()
print("weight grad 2:", "<rank {rank}>", model.weight.grad[0, 0].item())
# update parameters
optimizer.step()
print("weight update 2:", "<rank {rank}>", model.weight[0, 0].item())
def main():
world_size = 2
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
if __name__=="__main__":
# Environment variables which need to be
# set when using c10d's default "env"
# initialization mode.
os.environ["MASTER_ADDR"] = "localhost"
os.environ["MASTER_PORT"] = "29500"
main()
运行
python test.py
输出结果(不包括 # 后的内容)
init weight: <rank 1> -0.0235 # 注意初始化参数实际上不一致(与下一行对比)
init weight: <rank 0> -0.0271
weight grad 1: <rank 1> 0.0116 # 这一行在 backward 之后被打印, 因此梯度被平均了
weight grad 1: <rank 0> 0.0116
weight updated 1: <rank 1> -0.0387 # 这里很有趣, 更新后rank 1的权重跟rank 0一致了, 并且权重更新以 rank 0 为准
weight updated 1: <rank 0> -0.0387 # -0.0387 = -0.0271 - 1*0.0116
weight grad 2: <rank 1> 0.0289
weight grad 2: <rank 0> 0.0289
weight updated 2: <rank 1> -0.0676
weight updated 2: <rank 0> -0.0676
分析 1:
这里需要额外指出的一个要点是: 梯度是被平均的, 可以通过改写上面的程序做验证
- 怎么验证梯度是被平均的: 可以通过将
Linear的输入输出维度定为 1, 然后将模型输入定为 2,labels也设置为 1model = nn.Linear(1, 1, bias=False) if rank == 0: model.weight.data.fill_(2.) else: model.weight.data.fill_(200.) labels = torch.tensor([[1.]]).to(rank) - 过程猜想: 前向传播各自算,
backward时自动触发进程间通讯: 梯度用 reduce 操作做平均,optimizer.step操作似乎是先更新<rank 0>的参数, 然后把<rank 0>的参数广播给其他进程. - 但是上面的解释似乎不准确 (可以尝试将
<rank 0>的初始权重设为 2,<rank 1>的初始权重设为200), 输出结果如下: 注意只考虑一个进程时, 梯度的计算公式如下,loss = (w*1-1)**2, w.grad = 2*w-2, 由结果可以看出梯度是被平均的init weight: <rank 1> 200. init weight: <rank 0> 2. weight grad 1: <rank 1> 2. # 2=2*w-2=2*2-2 weight grad 1: <rank 0> 2. weight updated 1: <rank 1> 0. weight updated 1: <rank 0> 0. weight grad 2: <rank 1> -2. # -2=2*w-2=2*0-2 weight grad 2: <rank 0> -2. weight updated 2: <rank 1> 2. weight updated 2: <rank 0> 2.猜想可能在第一次前向传播时触发了一次通讯, 检查两个进程的权重是否一致, 如果不一致则在 backward 时以
<rank 0>为准, 然后第一次更新权重时需要将权重广播 (并设置一个标记表示权重已同步), 后面就可以免去参数广播这一步
分析 2:
注意看这个例子中使用的是 torch.multiprocessing.spawn, 并且搭配的是普通的脚本方式 python test.py, 这不是平时的典型用法. 而且注意到 torch.multiprocessing.spawn 的调用方式如下:
mp.spawn(example,
args=(world_size,),
nprocs=world_size,
join=True)
# example 实际上有 2 个参数, rank 与 world_size, 这里第一个参数 rank 会被分别自动传为 0, 1
DistributedSampler, torch.distributed.all_gather
# sampler.py
import torch
import os
import torch.distributed as dist
class DemoDataset(torch.utils.data.Dataset):
def __init__(self, n):
self._data = [i for i in range(n)]
def __getitem__(self, i):
return self._data[i] * 10
def __len__(self):
return len(self._data)
if __name__ == "__main__":
dist.init_process_group(backend="nccl")
world_size = os.environ["WORLD_SIZE"]
local_rank = os.environ["LOCAL_RANK"]
dataset = DemoDataset(16)
batch_size_per_gpu = 4
sampler = torch.utils.data.distributed.DistributedSampler(dataset, shuffle=True)
# 训练时总共的 batch_size 是 batch_size_per_gpu * world_size
dataloader = torch.utils.data.DataLoader(dataset, sampler=sampler, batch_size=batch_size_per_gpu)
for epoch in range(2):
sampler.set_epoch(epoch) # 注意设置这个!!
for item in dataloader:
item = item.to(local_rank) # 要手动移至 GPU
print(f"epoch {epoch}:", local_rank, "=>", item)
# 提前分配空间, to(local_rank) 是必要的
all_item = [torch.zeros(batch_size, dtype=torch.long).to(local_rank) for i in range(world_size)]
dist.all_gather(all_item, item) # 必须确保所有进程都执行 all_gather
print("epoch {epoch}:", local_rank, "all =>", all_item)
if local_rank == 0: # 一般来说这个区域打印日志或写文件
pass
# python -m torch.distributed.launch --nnodes 1 --nproc_per_node 2 sampler.py
输出
epoch 0: 0 => tensor([120, 90, 110, 130], device='cuda:0')
epoch 0: 1 => tensor([20, 150, 40, 70], device='cuda:1')
epoch 0: 0 all => [tensor([120, 90, 110, 130], device='cuda:0'), tensor([20, 150, 40, 70], device='cuda:0')]
epoch 0: 1 all => [tensor([120, 90, 110, 130], device='cuda:0'), tensor([20, 150, 40, 70], device='cuda:0')]
# 略 ...
torch.distributed.launch (Pytorch 1.9.0-)
使用
参考 Github 项目:分布式训练的例子
自己写的一个 demo: dist_example.py
这里简单提一下 train_script.py 的主要注意事项:
- 脚本开头必须初始化
dist.init_process_group(backend='nccl', init_method="env://") - 使用
DistributedDataParallel包裹原始的model# 预先设置默认的 cuda 也是好习惯 # torch.cuda.set_device(local_rank) model.cuda(local_rank) model = DistributedDataParallel(model, device_ids=[local_rank], output_device=local_rank) - 使用
DistributedSampler时的注意事项参考上节 - 在需要的地方需要插入
dist.all_gather,dist.reduce的通信函数 optimizer,torch.cuda.amp.GradScaler,torch.cuda.amp.autocast,scheduler的写法与单 GPU 无异
原理 & 源码
有时会见到以这种方式启动训练脚本
CUDA_VISIBLE_DEVICES=0,1,2,3,4,5,6,7 python -m torch.distributed.launch --nproc_per_node=8 --nnodes=1 --node_rank=0 --master_addr 127.0.0.1 --master_port 29500 train.py
上面运行脚本的参数以及一些基本概念含义解释如下:
local_rank指每个机器内部的 GPU 编号world_size指的是所有机器的 GPU 总数, 对应下面代码里的os.environ['WORLD_SIZE']nnodes: 机器数量node_rank: 机器编号nproc_per_node: 每个机器的进程数 (GPU 数量)master_addr: 用于通讯的进程地址(?)master_addr: 用于通讯的进程端口号(?)
torch 1.7.0 中 torch/distributed/launch.py 源码 (只去除了注释) 如下:
from __future__ import absolute_import, division, print_function, unicode_literals
import sys
import subprocess
import os
from argparse import ArgumentParser, REMAINDER
def parse_args():
parser = ArgumentParser()
# Optional arguments for the launch helper
parser.add_argument("--nnodes", type=int, default=1)
parser.add_argument("--node_rank", type=int, default=0)
parser.add_argument("--nproc_per_node", type=int, default=1)
parser.add_argument("--master_addr", default="127.0.0.1")
parser.add_argument("--master_port", default=29500, type=int)
parser.add_argument("--use_env", default=False, action="store_true")
parser.add_argument("-m", "--module", default=False, action="store_true")
parser.add_argument("--no_python", default=False, action="store_true")
# positional
parser.add_argument("training_script", type=str)
# rest from the training program
parser.add_argument('training_script_args', nargs=REMAINDER)
return parser.parse_args()
""" 备注: 使用下面的命令启动时
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 train.py --lr 0.2 --layers 34
training_srcipt为"train.py", training_script_args为["--lr", "0.2", "--layers", "34"]
"""
def main():
args = parse_args()
# world size in terms of number of processes
dist_world_size = args.nproc_per_node * args.nnodes
# set PyTorch distributed related environmental variables
current_env = os.environ.copy()
current_env["MASTER_ADDR"] = args.master_addr
current_env["MASTER_PORT"] = str(args.master_port)
current_env["WORLD_SIZE"] = str(dist_world_size)
processes = []
if 'OMP_NUM_THREADS' not in os.environ and args.nproc_per_node > 1:
current_env["OMP_NUM_THREADS"] = str(1)
print("Setting OMP_NUM_THREADS environment variable for each process "
"to be {} in default, to avoid your system being overloaded, "
"please further tune the variable for optimal performance in "
"your application as needed. \n".format(current_env["OMP_NUM_THREADS"]))
for local_rank in range(0, args.nproc_per_node):
# each process's rank
dist_rank = args.nproc_per_node * args.node_rank + local_rank
current_env["RANK"] = str(dist_rank)
current_env["LOCAL_RANK"] = str(local_rank)
# spawn the processes
with_python = not args.no_python
cmd = []
if with_python:
cmd = [sys.executable, "-u"] # sys.excutable由sys.argv[0]及若干个环境变量决定
if args.module:
cmd.append("-m")
else:
if not args.use_env:
raise ValueError("When using the '--no_python' flag, you must also set the '--use_env' flag.")
if args.module:
raise ValueError("Don't use both the '--no_python' flag and the '--module' flag at the same time.")
cmd.append(args.training_script)
if not args.use_env:
cmd.append("--local_rank={}".format(local_rank))
cmd.extend(args.training_script_args)
process = subprocess.Popen(cmd, env=current_env)
processes.append(process)
for process in processes:
process.wait() # 等待所有子进程结束
if process.returncode != 0:
raise subprocess.CalledProcessError(returncode=process.returncode,cmd=cmd)
if __name__ == "__main__":
main()
因此, 使用下面的命令启动训练脚本 train.py 时
python -m torch.distributed.launch --nproc_per_node=2 --nnodes=1 --node_rank=0 train.py --lr 0.2 --layers 34 -m 7
launch 脚本实际做的事情是利用 train.py 之前的参数设定创建进程的环境变量来创建多个进程:
# 两个进程的公共环境变量: MASTER_ADDR=127.0.0.1, MASTER_PORT=29500, WORLD_SIZE=2
# 进程 0: 设定了环境变量 RANK=0, LOCAL_RANK=0
python -u [-m] train.py --local_rank=0 --lr 0.2 --layers 34 -m 7
# 进程 1: 设定了环境变量 RANK=1, LOCAL_RANK=1
python -u [-m] train.py --local_rank=1 --lr 0.2 --layers 34 -m 7
备注
- 由于
argparse模块REMAINDER的特性, training_script_args 仍然可以包含["-m", "7"] - 使用 launch 脚本启动时,
train.py必须能解析--local_rank {local_rank}这个参数 (或者运行时添加--use_env)
torchrun (Pytorch 1.9.0+)
在 1.0.0-1.8.1 版本中,均使用 torch/distributed/launch.py(简称 launch.py)来启动。但在 1.9.0 及 1.9.1 版本中,官方文档中说 torch/distributed/run.py(简称 run.py)已被弃用,推荐用 run.py 来启动,而 1.9.0 与 1.9.1 版本的 launch.py 改为了调用 run.py 内的相关函数。而在 1.10.0 版本中,setup.py 文件引进了一项改动,又变为使用脚本 torchrun 进行启动,但实质上与 run.py 是一样的。而 1.9.0 版本的 run.py 本质上是调用了合并自 TorchElastic 的 torch.distributed.elastic 子模块下的内容。
??-1.9.1 版本的 setup.py 文件关于 entry_points 的写法:
entry_points = {
'console_scripts': [
'convert-caffe2-to-onnx = caffe2.python.onnx.bin.conversion:caffe2_to_onnx',
'convert-onnx-to-caffe2 = caffe2.python.onnx.bin.conversion:onnx_to_caffe2',
]
}
1.10.0 版本的 setup.py 文件关于 entry_points 的写法:
entry_points = {
'console_scripts': [
'convert-caffe2-to-onnx = caffe2.python.onnx.bin.conversion:caffe2_to_onnx',
'convert-onnx-to-caffe2 = caffe2.python.onnx.bin.conversion:onnx_to_caffe2',
'torchrun = torch.distributed.run:main',
]
}
总结一下:torch 1.8.1 及之前的 launch.py 文件实现逻辑及用法如上一节所述。torch 1.9.0 版本由于 TorchElastic 引入了 torch 中,所以使用了新的 run.py 作为启动文件(使用 TorchElastic 的功能),为保持兼容性,launch.py 的用法维持原状,但本质上也是在使用 run.py。
使用
太长不看: 从使用的角度, 从 launch.py 迁移至 run.py, 只需要关注以下两点即可
- 如果之前是使用
--use-env的方式启动, 这同时意味着train_script.py文件里是通过os.environ["LOCAL_RANK"]来获取local_rank的值python -m torch.distributed.launch --use-env [args] train_script.py [training_script_args] torchrun [args] train_script.py [training_script_args] python -m torch.distributed.run [args] train_script.py - 如果之前没有用
--use-env的方式启动, 这一般意味着train_script.py是通过argparser模块的--local_rank参数来获取local_rank的值# launch.py 的 train_script.py 脚本的写法 import argparse parser = argparse.ArgumentParser() parser.add_argument("--local-rank", type=int) args = parser.parse_args() local_rank = args.local_rank # run.py 的 train_script.py 脚本的写法 import os local_rank = int(os.environ["LOCAL_RANK"])原理
具体的实现超出了本文的范畴, 这里只关注一下 run.py 的大概写法, 注意 run.py 实际上除了兼容 launch.py 的 master_addr 等参数外, 还提供了许多额外参数, 但一般无需关心
# 备注: huggingface accelerate 对 ddp 的集成就是使用了 run 函数
def run(args):
if args.standalone:
args.rdzv_backend = "c10d"
args.rdzv_endpoint = "localhost:0"
args.rdzv_id = str(uuid.uuid4())
# config: LaunchConfig
# cmd: python 的绝对路径
# cmd_args: -u [-m] train_script.py [--other 1]
config, cmd, cmd_args = config_from_args(args)
elastic_launch(
config=config,
entrypoint=cmd,
)(*cmd_args)
@record
def main(args=None):
args = parse_args(args)
run(args)
if __name__ == "__main__":
main()
多机多卡
原理
参考文献:
- 一篇中文博客: https://www.cnblogs.com/rossiXYZ/p/15553384.html
- 一篇英文博客: https://www.telesens.co/2019/04/04/distributed-data-parallel-training-using-pytorch-on-aws/