(Alpha) T5 详解
动机、参考资料、涉及内容
动机
- 熟悉 🤗 Transformers 的相关 API 与源码
- 熟悉 🤗 Tokenizers 的相关 API 与源码
- 深入理解 T5 的训练与推理步骤,包括每一步的计算过程
- 适当补充相关知识
参考资料
- 🤗 Transformers 4.26.1 源代码
- 🤗 Transformers 官方文档
- T5原始论文
- 论文地址:https://arxiv.org/pdf/1910.10683.pdf
- 标题:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer
- 机构:Google
注意事项
主要从两个视角来写这篇博客:
- 原理视角:主要是论文里描述为主,但缺点是某些地方可能会有一定的模糊
- 实现视角:以 🤗 Transformers 的实际实现为准
Overview: T5
T5 模型尝试将所有的 NLP 任务做了一个统一处理,即:将所有的 NLP 任务都转化为 Text-to-Text 任务。如原论文下图所示:
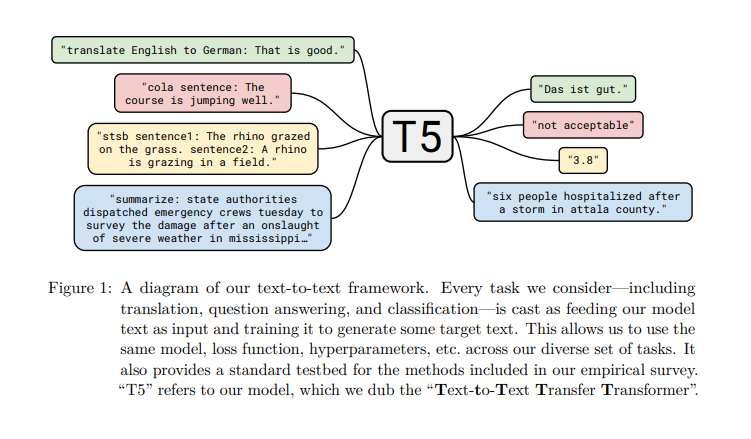
绿色的框是一个翻译任务(英文翻译为德文),按照以往标准的翻译模型的做法,模型的输入为:That is good.,期望模型的输出为:Das ist gut.,而 T5 的做法是将输入转化为:translate English to German: That is good.,期望的输出依然维持原样。也就是将 NLP 任务的描述也加在了模型输入里。原文中附录 D 中给出了更多的例子。
在模型结构上,T5 模型采用了 Encoder-Decoder 的架构,从大体上说,对于训练过程,伪代码如下:
x, y = "translate English to German: That is good.", "Das ist gut."
x = tokenizer(x) # [0, 23, 45, 89, 1230, 4, 9], 其中0代表<BOS>, 在实现中<PAD>也是0
y = tokenizer(y) # [0, 44, 156, 4, 1], 其中1代表<EOS>
x_embedding = encoder.embed_layer(x) # 将token转换为embedding, x_embedding的形状为(7, 768)
encoded_x = encoder.other_layer(x_embedding) # 经过encoder后encoded_x的形状为(7, 768)
input_y = y[:-1] # [0, 44, 156, 4]
# 将token转化为emdedding, input_y_emdedding的形状为(4, 768)
input_y_emdedding = decoder.embed_layer(input_y) # 在T5的设计中,encoder.embed_layer与decoder.embed_layer共享参数
target_y = y[1:] # [44, 156, 4, 1]
# decoder_output的形状为(4, 768)
decoder_output = decoder.other_layer(encoded_x, input_y_emdedding)
# logits 的形状为(4, vocab_size=32128)
logits = linear_layer(decoder_output) # 在T5的设计中,decoder.embed_layer与linear_layer共享参数
# 接下来使用 softmax 与普通的交叉熵计算损失
loss = loss_fn(logits, target_y)
Overview: 🤗 Transformers
对于 🤗 Transformers 的源码阅读而言,本文主要的关注点在于以下部分,首先 🤗 Transformers github 项目的目录结构如下(节选)
examples # 一些示例代码, 可供学习, 但不确保能与当前版本兼容
- flax/language-modeling/t5_tokenizer_model.py # t5 tokenizer 训练参考
- flax/language-modeling/run_t5_mlm_flax.py # t5 mask-LM 预训练参考
- pytorch/summarization # t5 生成式模型训练参考
src/transformers
- generation/
- beam_constraints.py # constraint_beam_search 辅助方法/类: Constraint, ConstraintListState
- beam_search.py # beam_search 辅助方法/类: BeamSearchScorer, ConstrainedBeamSearchScorer, BeamHypotheses
- configuration_utils.py # 生成式模型的统一配置文件, 用来控制生成算法及各类超参数, 例如生成长度惩罚
- logit_process.py # 生成过程时对log-softmax score的后处理:LogitsProcessor, LogitsWarpper
- stopping_criteria.py # 生成中止条件:StoppingCriteria
- streamer.py # transformers 4.28.0 版本新增, 用于生成字符时流式逐词输出
- utils.py # GenerationMixin 的实现
...
- models/ # 每个模型为一个单独的文件夹, 每个文件夹的文件结构比较固定, 参考t5子文件夹
- t5/
- __init__.py
- convert_t5_original_tf_checkpoint_to_pytorch.py # 有些模型原始官方仓库的权重需要通过转换得到 🤗 Transformers 中模型定义下模型载入的格式, 这种情况下会维护一个转换脚本
- modeling_flax_t5.py # flax版本的模型结构代码, 本文不涉及
- modeling_tf_t5.py # tensorflow版本的模型结构代码, 本文不涉及
- modeling_t5.py # pytorch版本的模型结构代码
- configuration_t5.py # 每个模型都有一个自己的模型结构参数配置文件
- tokenization_t5.py # 每个模型的slow/python版本的tokenizer实现, 速度相对较慢
- tokenization_t5_fast.py # 每个模型的fast版本的tokenizer实现, 速度较快, 依赖于 🤗 Tokenizers
- ...
- ...
- pipelines/ # 封装tokenizer与model, 简化使用, 本文不涉及
- modeling_outputs.py # 模型输出结果的数据结构
- modeling_utils.py # 所有模型的基类: PreTrainedModel
- tokenization_utils_base.py # 所有tokenizer的基类: PreTrainedTokenizerBase
- tokenization_utils.py # 所有slow版本tokenizer的基类: PreTrainedTokenizer
- tokenization_utils_fast.py # 所有fast版本tokenizer的基类: PreTrainedTokenizerFast
- trainer.py # Trainer类, 本文不涉及
- trainer_callback.py # Trainer类中使用到的 TrainerCallback/TrainerState/TrainerControl/CallbackHandler
- integrations.py # 高级日志记录工具, 例如: TensorBoardCallback
- ...
原理解析:T5 训练过程的前向计算流程
encoder
首先给出总体的结构图
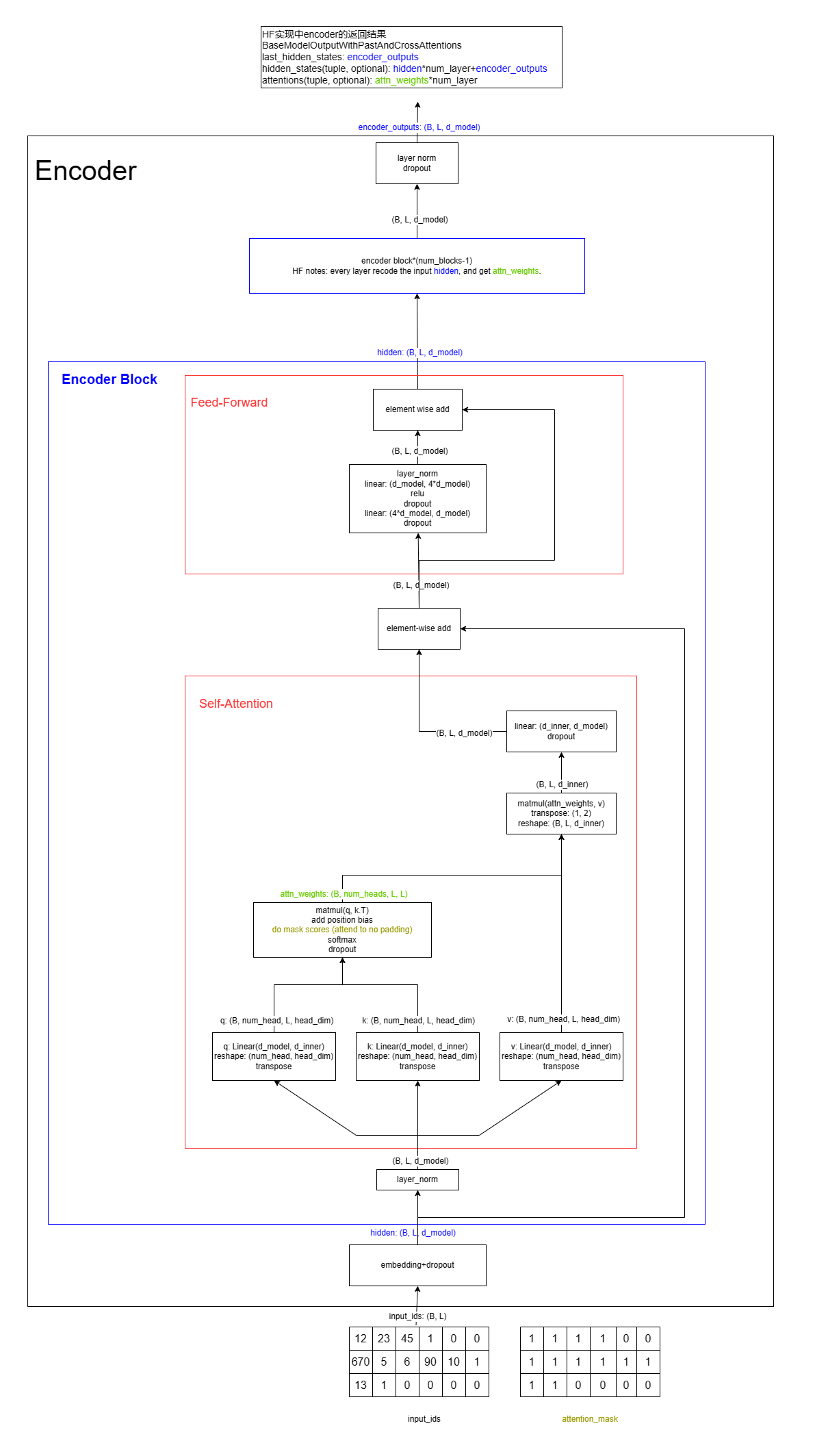
T5 模型的 Encoder 部分由若干个 Block 构成,每个 Block 都具有相同的结构:一个 Self-Attention Layer 和一个 Feed-Forward Layer。这里也首先给出伪代码:
class Encoder:
def forward(self, x_token, x_attention_mask):
# x_token: (B, L=512), long
# x_attention: (B, L), 0/1 mask
x_embedding = embedding_layer(x_token)
hidden = dropout(x_embedding) # (B, L, C=768)
positional_bias = None
for block in blocks:
hidden_1 = block.layernorm_layer(hidden) # LayerNorm层, hidden_1: (B, L, C)
# Self-Attention层, attention_hidden: (B, L, C), postional_bias: (1, n_heads, L, L)
# postional_bias在第一层被产生, 后面每一层都使用它(共享参数)
attention_hidden, positional_bias = block.attention_layer(hidden_1, x_attention_mask, positional_bias)
hidden = block.dropout(attention_hidden) + hidden # 残差连接: hidden: (B, L, C)
hidden = block.ff_layer(hidden) # Feed-Forward层: hidden (B, L, C)
hidden = layernorm_layer(hidden) # hidden (B, L, C)
hidden = dropout(hidden) # hidden (B, L, C)
return hidden
备注:在 🤗 Transformers 的实现中,将此处的 block.layernorm_layer, block.attention_layer、block.dropout 的计算逻辑包装在了一起,称为 T5LayerSelfAttention。而此处的 block.ff_layer 为 T5LayerFF。
LayerNorm Layer (Encoder)
class LayerNorm(torch.nn.Module):
def __init__(self, hidden_size, eps=1e-6):
super().__init__()
self.weight = nn.Parameter(torch.ones(hidden_size))
self.variance_epsilon = eps
def forward(self, hidden_states):
# T5用的是简化版的layernorm对最后一维l2归一化后再每一维乘上一个权重, 不带偏置项
# hidden_states: (B, L, C)
# return: (B, L, C)
variance = hidden_states.to(torch.float32).pow(2).mean(-1, keepdim=True)
hidden_states = hidden_states * torch.rsqrt(variance + self.variance_epsilon)
return self.weight * hidden_states
Self-Attention Layer (Encoder)
relative positional embedding
总共的 postional embedding 数目为 (num_bucket, n_head), T5 的 postional embedding 的 index 的取值范围为 [0, num_bucket)
双向 mask 的情况下, $n=num_bucket, m=max_distance$
\[\begin{equation*} index(i, j) = \frac{n}{2} * \mathbb{1}[i-j<0] + \left\{ \begin{aligned} &abs(i - j), &abs(i - j) < \frac{n}{4} \\ &\min(\frac{n}{2}-1, \frac{n}{4}\times(1+\frac{log(4\times abs(i - j)/n)}{log(4\times m/n)})), &abs(i - j) \ge \frac{n}{4} \end{aligned} \right. \end{equation*}\]def relative_position_bidirectional(i, j, num_buckets=32, max_distance=128):
position = i - j
abs_position = abs(position)
num_buckets = num_buckets // 2
max_exact = num_buckets // 2
offset = num_buckets if position < 0 else 0
if abs_position < max_exact:
return abs_position + offset
else:
ratio = math.log(abs_position/ max_exact) / math.log(max_distance / max_exact)
return min(int(max_exact*(1+ratio)), num_buckets - 1) + offset
casual mask 的情况下,
\[\begin{equation*} index(i, j) = \left\{ \begin{aligned} &0, &i \ge j \\ &abs(i - j), &i < j\ and\ abs(i - j) < \frac{n}{2} \\ &\min(n-1, \frac{n}{2}\times(1+\frac{log(2\times abs(i - j)/n)}{log(2\times m/n)})), &i < j\ and\ abs(i - j) \ge \frac{n}{2} \end{aligned} \right. \end{equation*}\]def relative_position_onedirectional(i, j, num_buckets=32, max_distance=128):
position = i - j
if position <= 0:
return 0
elif position < (num_buckets // 2):
return position
else:
ratio = math.log(2 * position / num_buckets) / math.log(2 * max_distance / num_buckets)
return min(int(num_buckets // 2 * (1 + ratio)), num_buckets - 1)
在 T5 模型的实验设置中:
num_bucket, max_distance = 32, 128
在 encoder 与 decoder 的第一层加上了 positional bias:
bias = nn.Embedding(num_buckect, n_heads)
positional_idx = ... # 即上面的公式, (L, L)
scores = q @ k.T # (B, L, L, n_heads)
positional_bias = bias(positional_idx) # (L, L, n_heads)
scores += positional_bias
# weights = softmax(scores)
self-attention
class EncoderSelfAttention(torch.nn.Module):
def __init__(self, d_model=768, d_qkv=64, n_heads=12,
relative_attention_num_buckets=32, has_relative_bias=False, dropout_rate=0.1):
"""
relative_attention_num_buckets: 见后面关于positional bias的说明
has_relative_bias: 第1个EncoderBlock取值为True, 其余均为False
"""
super().__init__()
self.inner_dim = d_qkv * n_heads
self.q, self.k, self.v = [nn.Linear(d_model, self.inner_dim) for i in range(3)]
self.o = nn.Linear(self.inner_dim, d_model)
self.dropout_rate = dropout_rate
if has_relative_bias:
self.relative_attention_bias = nn.Embedding(self.relative_attention_num_buckets, self.n_heads)
def compute_bias(self, q_len=512, k_len=512):
# q_len和k_len都是encoder输入的序列长度
# 在decoder的self-attention的训练阶段, q_len和k_len都是decoder的输入长度
# positions: (q_len, k_len) long tensor
# 每个元素的取值范围都是[0, self.relative_attention_num_buckets=32)
positions = get_relative_idx(q_len, k_len)
bias = self.relative_attention_bias(positions).unsqueeze(0) # (1, q_len, k_len, n_heads)
bias = bias.transpose(0, 3, 1, 2)
# bias: (1, n_heads, q_len, k_len), 其中第0维在计算中被广播, 即(B, n_heads, q_len, k_len)
return bias
def forward(self, hidden, attention_mask, bias=None):
"""
Args:
hidden: (B, L, d_model)
attention_mask: (B, L) LongTensor, 有token的地方为1, pad处为0
bias: 第1层输入为None, 后续层将第一层输出的bias作为输入
"""
# q, k, v: (B, L, self.inner_dim)
q, k, v = self.q(hidden), self.k(hidden), self.v(hidden)
q = q.reshape(B, L, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, L=q_len, d_qkv)
k = k.reshape(B, L, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, L=k_len, d_qkv)
v = v.reshape(B, L, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, L=k_len, d_qkv)
scores = torch.matmul(q, k.transpose(2, 3)) # (B, n_head, L, L)
if bias is None:
bias = self.compute_bias(L, L) # (1, n_head, L, L)
extended_mask = torch.where(attention_mask[:, None, None, :]==1, 0, -inf) # (B, 1, 1, L)
bias = bias + extended_mask # (B, n_head, L, L)
scores += bias
attn_weights = nn.functional.softmax(scores, dim=-1)
attn_weights = nn.functional.dropout(attn_weights, self.dropout_rate)
hidden = torch.matmul(atten_weights, v) # (B, n_heads, L, d_qkv)
hidden = hidden.transpose(1, 2).view(B, L, self.inner_dim) # (B, L, inner_dim)
hidden = self.o(hidden) # (B, L, d_model)
return hidden, bias
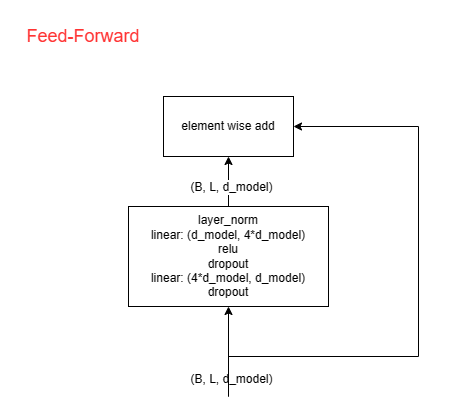
Feed-Forward
见下图,含义自明
decoder
首先给出总体的结构图
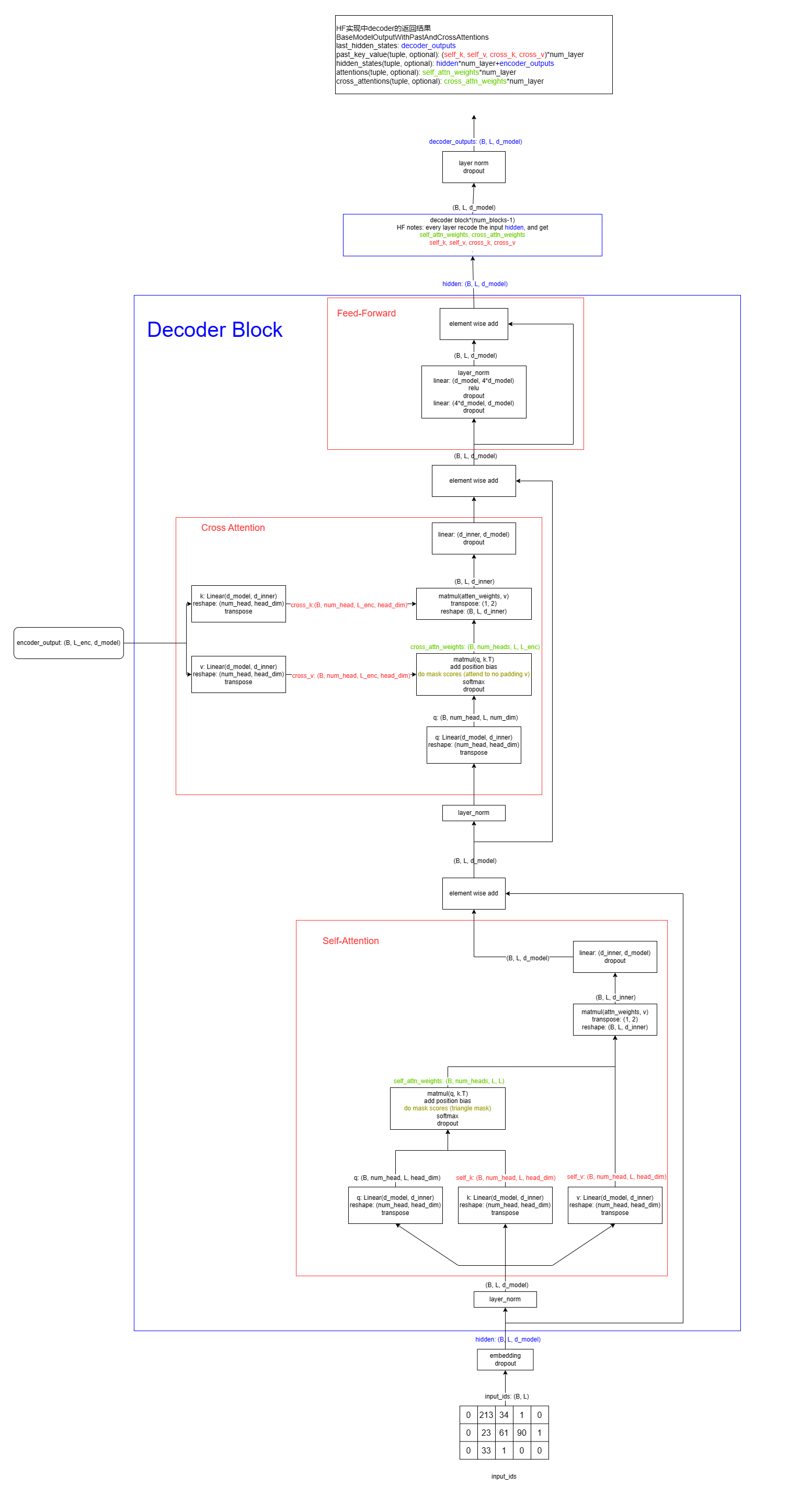
Self-Attention Layer (Decoder)
与 Self-Attention Layer(Encoder) 的计算过程一致, 但有如下两个区别:
-
positional bias 使用单向的方式进行获取
-
mask有些变化:bias = self.compute_bias(L, L) # (1, n_head, L=trg_len, L=trg_len) mask = torch.triu(torch.ones((B, 1, L, L))) # (B, 1, L, L), 下三角含对角线为1, 其余均为0 extended_mask = torch.where(mask==1, 0, -inf) # 下三角含对角线为0, 其余均为-inf bias = bias + extended_mask # (B, n_head, L, L)
Cross-Attention Layer (Decoder)
class DecoderCrossAttention(torch.nn.Module):
def __init__(self, d_model=768, d_qkv=64, n_heads=12, dropout_rate=0.1):
# 没有postion bias的计算
super().__init__()
self.inner_dim = d_qkv * n_heads
self.q, self.k, self.v = [nn.Linear(d_model, self.inner_dim) for i in range(3)]
self.o = nn.Linear(self.inner_dim, d_model)
self.dropout_rate = dropout_rate
def forward(self, decoder_hidden, encoder_hidden, encoder_attention_mask):
"""
Args:
decoder_hidden: (B, trg_len, d_model)
encoder_hidden: (B, src_len, d_model)
encoder_attention_mask: (B, L) LongTensor, 输入序列有token的地方为1, pad处为0
"""
q, k, v = self.q(decoder_hidden), self.k(encoder_hidden), self.v(encoder_hidden)
q = q.reshape(B, trg_len, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, q_len=trg_len, d_qkv)
k = k.reshape(B, src_len, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, k_len=src_len, d_qkv)
v = v.reshape(B, src_len, n_heads, d_qkv).transpose(1, 2) # (B, n_heads, k_len=src_len, d_qkv)
scores = torch.matmul(q, k.transpose(2, 3)) # (B, n_heads, trg_len, src_len)
bias = torch.zeros(B, n_heads, trg_len, src_len) # (1, n_heads, trg_len, src_len)
extended_mask = torch.where(attention_mask[:, None, None, :]==1, 0, -inf) # (B, 1, 1, src_len)
bias = bias + extended_mask # (B, n_heads, trg_len, src_len)
scores += bias
attn_weights = nn.functional.softmax(scores, dim=-1)
attn_weights = nn.functional.dropout(attn_weights, self.dropout_rate)
hidden = torch.matmul(atten_weights, v) # (B, n_heads, trg_len, d_qkv) = (B, n_heads, trg_len, src_len) * (B, n_heads, src_len, d_qkv)
hidden = hidden.transpose(1, 2).view(B, trg_len, self.inner_dim) # (B, trg_len, inner_dim)
hidden = self.o(hidden) # (B, trg_len, d_model)
return hidden, bias
源码解析:🤗 Transformers 中 T5 训练过程的前向计算流程
如果对T5的计算逻辑基本熟悉的话,这里给出 🤗 Transformers 中的模型层次,可以帮助快速理解源码的实现逻辑:
# 注意: T5Attention 这个类同时实现了三类注意力机制
T5ForConditionalGeneration:
- nn.Embedding # A
- encoder: T5Stack
- nn.Embedding # 与 A 是同一个
- T5Block
- T5LayerSelfAttention
- T5LayerNorm
- T5Attention # 全自注意力, 位于第一个T5Block中此模块含有一个nn.Embedding用于学习relative postional bias, 可学习参数形状:(num_bucket=32, num_heads=64)
- nn.Dropout
- T5LayerFF
- T5Block
...
- T5Block
- T5LayerNorm
- nn.Dropout
- decoder: T5Stack
- nn.Embedding # 与 A 是同一个
- T5Block
- T5LayerSelfAttention
- T5LayerNorm
- T5Attention # 因果自注意力, 位于第一个T5Block中此模块含有一个nn.Embedding用于学习relative postional bias, 可学习参数形状:(num_bucket=32, num_heads=64)
- nn.Dropout
- T5LayerCrossAttention
- T5LayerNorm
- T5Attention # 与encoder的输出做注意力, 没有relative postional bias
- nn.Dropout
- T5LayerFF
- T5Block
...
- T5Block
- T5LayerNorm
- nn.Dropout
- nn.Linear # T5中的设计里与 A 共享参数
备注:在 🤗 Transformers 的源码实现里 T5Attention 比较复杂,它需要承担几项不同的工作:
- 训练阶段:
- 在 encoder 中执行全自注意力机制
- 在 decoder 中的
T5LayerSelfAttention中执行因果自注意力机制(训练时因为可以并行计算整个decoder序列的各个隐层向量,不需要考虑decoder前序token的key和value的缓存) - 在 decoder 中的
T5LayerCrossAttention中执行对encoder输出的注意力机制(训练时因为可以并行计算整个decoder序列的各个隐层向量,不需要考虑encoder最后一层的key和value的缓存)
- 推理阶段:
- 在 encoder 中执行全自注意力机制,与训练时完全一致
- 在 decoder 中的
T5LayerSelfAttention中执行因果自注意力机制(推理时是串行解码,因此需要缓存decoder的之前所有token的key和value的缓存,计算当前token的隐层向量时也把当前token的key和value也缓存下来供后续计算) - 在 decoder 中的
T5LayerCrossAttention中执行对encoder输出的注意力机制(推理时是串行解码,因此解码第一个字符时会缓存每一层针对encoder输出向量的key和value,解码后续字符时直接使用这些key和value缓存进行计算)
下面将不再按照 🤗 Transformers 的源码进行梳理,而是直接手写大部分层的实现来讲解,手写实现与 🤗 Transformers 实现的对应也在各小节给出。更为完整的对应关系可以参考:../assets/code/t5
源码解析:🤗 Transformers PretrainedModel【TODO】
repeat yourself 的典型例子:t5 与 mt5 代码完全相同
PretrainedModel 类有 4 个基类:
nn.Module: pytorch 模型基类ModuleUtilsMixin: 见下面描述GenerationMixin: 与文本生成相关的方法, 见后文描述PushToHubMixin: 对外方法仅有一个push_to_hub, 作用是将模型推送至 🤗 Hub 仓库, 此处不赘述
ModuleUtilsMixin 的方法穷举
memory hook
相关方法如下:
add_memory_hooks: 为self.modules()增加内存增加监控的 hook,使用到了以下的三个方法_hook_rss_memory_pre_forward_hook_rss_memory_post_forwardreset_memory_hooks_state
mask 相关【待补充】
invert_attention_maskcreate_extended_attention_mask_for_decoderget_extended_attention_maskget_head_mask_convert_head_mask_to_5d
device、dtype、num_parameters、estimate_tokens、floating_point_ops
device: 注意nn.Module没有这个属性, 这里用self里的 tensor 来获取 device 信息 (假设所有的 tensor 都在同一个 device 上)dtype: 与device原理相同num_parameters(only_trainable=False, exclude_embeddings=False): 统计模型的参数量estimate_tokens(input_dict: Dict[str, torch.Tensor]): 辅助函数, 大多数时候用于统计input_ids的元素个数floating_point_ops(input_dict, exclude_embeddings=True): 参考论文, 给出模型计算的浮点数运算次数, 估计值为:6 * self.estimate_tokens(input_dict) * self.num_parameters(exclude_embeddings=exclude_embeddings)
PretrainedModel 的方法与类属性穷举【待补充】
属性
class PretrainedModel:
config_class = None
base_model_prefix = ""
main_input_name = "input_ids"
_auto_class = None
_no_split_modules = None
_keep_in_fp32_modules = None
# a list of `re` patterns of `state_dict` keys that should be removed from the list of missing
# keys we find (keys inside the model but not in the checkpoint) and avoid unnecessary warnings.
_keys_to_ignore_on_load_missing = None
# a list of `re` patterns of `state_dict` keys that should be removed from the list of
# unexpected keys we find (keys inside the checkpoint but not the model) and avoid unnecessary
# warnings.
_keys_to_ignore_on_load_unexpected = None
# a list of `state_dict` keys to ignore when saving the model (useful for keys that aren't
# trained, but which are either deterministic or tied variables)
_keys_to_ignore_on_save = None
is_parallelizable = False
supports_gradient_checkpointing = False
实例化相关
牵涉到如下方法
from_pretrained: 最为重要的方法__init___load_pretrained_model_load_pretrained_model_low_mem
post_initinit_weightsprune_heads: 需要实现self.base_model._prune_heads_init_weights: 由子类重载tie_weights:_tie_encoder_decoder_weights_tie_or_clone_weights- 调用
self.modules()实现的_tie_weights(如果有实现的话)
_backward_compatibility_gradient_checkpointing
_from_config: classmethod
resize token
牵涉到的方法如下
resize_token_embeddings_resize_token_embeddings
_get_resized_embeddings_get_resized_lm_headresize_position_embeddings: 需要子类实现【是否必须】get_position_embeddings: 需要子类实现【是否必须】
save_pretrained
save_pretrained
获取信息
dummy_inputs:framework:can_generate:base_model:return getattr(self, self.base_model_prefix, self)get_input_embeddings: 默认使用self.base_model.get_input_embeddings()set_input_embeddings: 默认使用self.base_model.set_input_embeddings()
get_output_embeddings: 子类重载此方法【作用是什么】retrieve_modules_from_names
activation checkpointing
gradient_checkpointing_enablegradient_checkpointing_disableis_gradient_checkpointing
auto class
register_for_auto_class
其他【待补充】
_set_default_torch_dtypeget_memory_footprinttohalffloat
原理/源码解析:🤗 Transformers 中的文本生成策略
本节介绍 🤗 Transformers 里各种生成方式的详细算法
关于文本生成,🤗 Transformers 官方有如下几篇博客值得阅读:
- 基础篇-各类生成策略:how-to-generate
- 4.24.0版本(发布时间2022/11/01)引入contrastive search:contrastive-search
使用 🤗 Transformers 生成文本,用法如下:
from transformers import T5Tokenizer, T5ForConditionalGeneration
pretrained_name_or_path = "t5-small"
tokenizer = T5Tokenizer.from_pretrained(pretrained_name_or_path)
model = T5ForConditionalGeneration.from_pretrained(pretrained_name_or_path)
inputs = tokenizer(["I'm a student, ", "Deep learning"])
generated_ids = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
max_length=32,
num_beams=5,
repetition_penalty=2.5,
length_penalty=1.0,
early_stopping=True
)
这里的 generate 函数是实现在 T5ForConditionalGeneration 的基类 PreTrainedModel 中的,而 generate 方法会根据传入的参数(例如这个例子里的 max_length, num_beams, repetition_penalty, length_penalty, early_stopping)选择更为具体的生成方式进行生成, 这些生成方式也都是在基类 PreTrainedModel 中进行实现的, 由此可以看出在生成策略上其实对于不同的模型是统一的。这些更为具体的生成方式列举如下,后面再加以详细介绍:
greedy_search:贪心策略beam_search:beam searchsample:对每次得到的概率分布上进行采样beam_sample:对每次得到的概率分布上进行采样后再进行 beam searchgroup_beam_search:对 beam_size 进行分组, 每组分别使用 beam search, 以提升 beam search 结果的多样性constrained_beam_search:带约束条件的 beam search, 例如生成结果里必须要包含特定的词contrastive_search:这篇论文里提出的一种生成方式,改善了 greedy search/beam search 生成结果经常出现重复句子(文献中成为 model degeneration)的情况, 也改善了 sample/beam sample 方法容易出现语义前后不一致的现象。
阅读 how-to-generate 博客的读者,可能会疑惑于 top k sampling 与 top p sampling (top p)实现在哪里, 这里给出简要的解释:这两个被抽象为对抽样过程概率分布的调整,因此插在概率分布与采样之间。另外,目前为止比较公认的相对优秀生成方式为带有 top p/top k 的 beam sample 方式,并且需要适当调节 length_penalty 参数用以促进/抑制生成的序列长度,调节 repetition_penalty 等相关参数控制重复词组出现的次数。总的来说,调整这些参数对生成质量还是有一些影响的,因此在 decoder 的解码策略上也一直有论文进行研究(例如:contrastive search 是 2022 年的工作),不同的大模型在开发过程中也可能会探索出新的生成策略。
本节后续内容组织如下:
- 关于 generate 方法的简要介绍,涉及到
PreTrainedModel的一些继承关系 GenerationConfig的简介:只简单介绍一部分参数,其余的参考官方文档。重点介绍跟生成策略强相关的参数- 最简版本的
greedy search介绍 LogitsProcessor、LogitsWarpper简介beam_searchsample/beam_samplegroup_beam_searchconstrained_beam_search: 这个方法自成体系且实现上有些复杂, 需要额外介绍相关的实现细节contrastive_search
PreTrainedModel, GenerationMixin, generate
本节主要按照 🤗 Transformers 的源码进行介绍,按照 🤗 Transformers 中的实现,T5ForConditionalGeneration 的继承关系如下:
class T5ForConditionalGeneration(T5PreTrainedModel):
# 用于 load 权重时可以忽略
_keys_to_ignore_on_load_missing = [
r"encoder.embed_tokens.weight",
r"decoder.embed_tokens.weight",
r"lm_head.weight",
]
_keys_to_ignore_on_load_unexpected = [
r"decoder.block.0.layer.1.EncDecAttention.relative_attention_bias.weight",
]
# ...
class T5PreTrainedModel(PreTrainedModel):
config_class = T5Config
base_model_prefix = "transformer" # 在 from_pretrained 函数中 load 权重时有用
def _init_weights(self, module):
...
# 其他一些方法和属性从略
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin):
pass
而与生成相关的代码主要实现在 GenerationMixin 中,一般而言,通过这个类的 generate 方法进行使用,根据不同的参数设定,会实际上通过调用以下 7 种方法来完成实际的生成:
generate 方法如下:
def generate(
self,
inputs: Optional[torch.Tensor] = None,
generation_config: Optional[GenerationConfig] = None,
logits_processor: Optional[LogitsProcessorList] = None,
stopping_criteria: Optional[StoppingCriteriaList] = None,
prefix_allowed_tokens_fn: Optional[Callable[[int, torch.Tensor], List[int]]] = None,
synced_gpus: Optional[bool] = False,
**kwargs):
# 只摘录核心部分
if generation_config is None:
generation_config = self.generation_config
generation_config = copy.deepcopy(generation_config)
# 根据kwargs更新
model_kwargs = generation_config.update(**kwargs) # All unused kwargs must be model kwargs
self._validate_model_kwargs(model_kwargs.copy())
logits_processor = logits_processor if logits_processor is not None else LogitsProcessorList()
stopping_criteria = stopping_criteria if stopping_criteria is not None else StoppingCriteriaList()
inputs_tensor, model_input_name, model_kwargs = self._prepare_model_inputs(
inputs, generation_config.bos_token_id, model_kwargs
)
# 再根据generation_config增加一部分logits_processor
logits_processor = self._get_logits_processor(generation_config, input_ids_seq_length, encoder_input_ids,
prefix_allowed_tokens_fn, logits_processor)
# 再根据generation_config增加一部分stopping_criteria
stopping_criteria = self._get_stopping_criteria(generation_config, stopping_criteria)
# 根据不同的generation_config设置, 分别调用上述7种方法
...
备注:此处的 generation_config 变量的类型为 GenerationConfig, 而 self.generation_config 是 PreTrainedModel 实例化时得到的。
【此处需增加一个隐藏按钮】
class PreTrainedModel(nn.Module, ModuleUtilsMixin, GenerationMixin, PushToHubMixin):
def __init__(self, config, *inputs, **kwargs):
# *inputs, **kwargs 在此处未被使用到
super().__init__() # nn.Module的__init__函数, 其余继承类均为Mixin, 没有__init__函数
self.config = config
self.name_or_path = config.name_or_path
self.warnings_issued = {}
self.generation_config = GenerationConfig.from_model_config(config) if self.can_generate() else None
@classmethod
def from_pretrained(self, pretrained_model_name_or_path, *model_args, **kwargs):
# 只摘录重要的部分
config = kwargs.pop("config", None)
if not isinstance(config, PretrainedConfig):
config_path = config if config is not None else pretrained_model_name_or_path
config, model_kwargs = cls.config_class.from_pretrained(..., **kwargs)
else:
model_kwargs = kwargs
model = cls(config, *model_args, **model_kwargs) # 调用 __init__
state_dict = load_state_dict(resolved_archive_file)
model, ... = cls._load_pretrained_model(model, state_dict, ...) # load权重至模型
model.eval() # 将模型设置为eval模式
if model.can_generate(): # 如果pretrained_model_name_or_path目录下包含generation_config.json文件, 则按这个文件重新初始化model.generation_config
model.generation_config = GenerationConfig.from_pretrained(pretrained_model_name_or_path, ..., **kwargs)
def save_pretrained(self, save_directory, ...):
# 只摘录重要的部分
os.makedirs(save_directory, exist_ok=True)
model_to_save = unwrap_model(self)
if is_main_process:
model_to_save.config.save_pretrained(save_directory)
if self.can_generate():
model_to_save.generation_config.save_pretrained(save_directory)
if state_dict is None:
state_dict = model_to_save.state_dict()
# 某些参数在保存时可以忽略
if self._keys_to_ignore_on_save is not None:
for ignore_key in self._keys_to_ignore_on_save:
if ignore_key in state_dict.keys():
del state_dict[ignore_key]
# 在正常情况下(模型参数不多), shard是一个只有一个键值对的字典, key为"pytorch_model.bin", value即为state_dict
weights_name = SAFE_WEIGHTS_NAME if safe_serialization else WEIGHTS_NAME
shards, index = shard_checkpoint(state_dict, max_shard_size=max_shard_size, weights_name=weights_name)
for shard_file, shard in shards.items():
if safe_serialization:
safe_save_file(shard, os.path.join(save_directory, shard_file), metadata={"format": "pt"})
else:
save_function(shard, os.path.join(save_directory, shard_file))
# 保存index
...
GenerationConfig 的主要参数【TODO】
greedy_search
图解如下
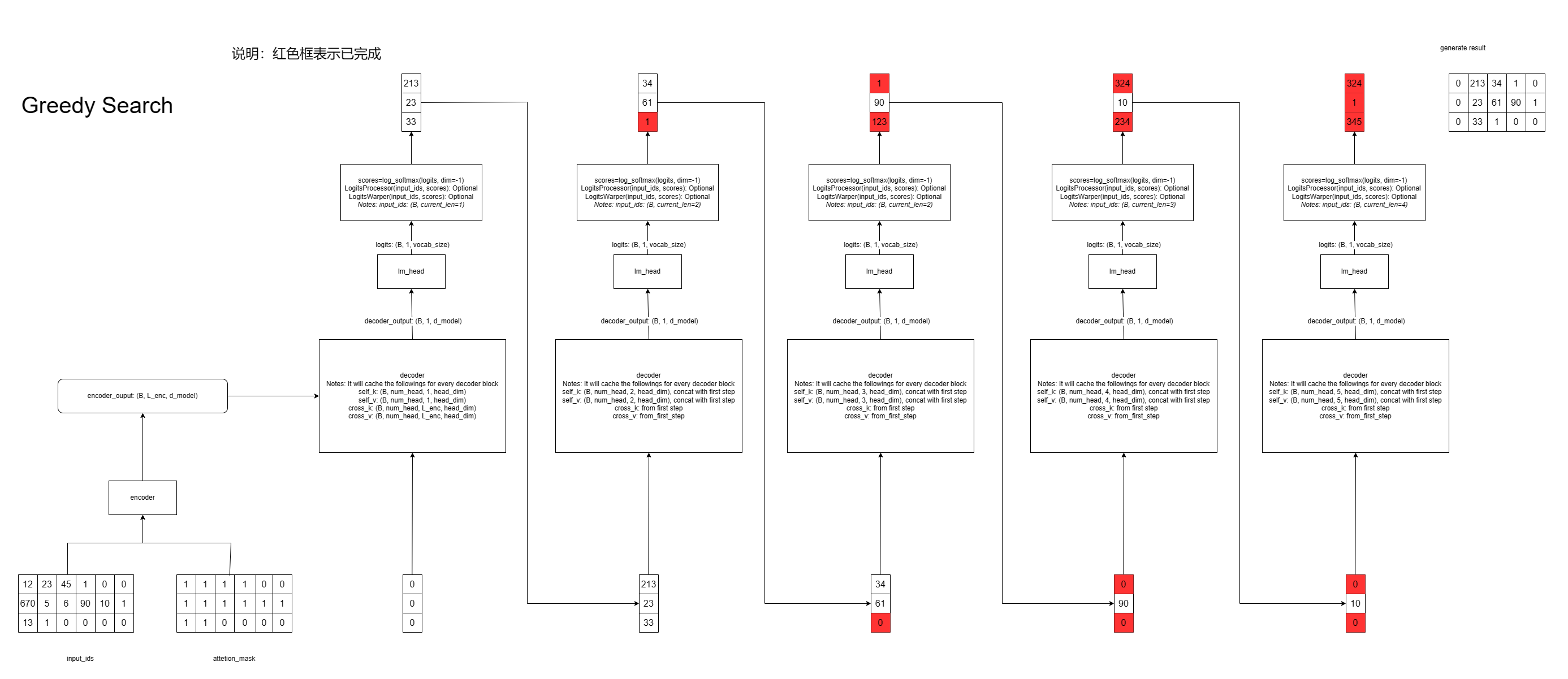
LogitsProcessor、LogitsWarpper、StoppingCriteria【TODO】
beam_search
- 当 beam_size 为 1 时退化为 greedy_search
logits_processor: 实际上是对当前预测的log-softmax分数进行后处理(例如重复出现的字做些score上的惩罚)
stopping_criteria: 判断是否应该结束, 返回True表示应该结束(最典型的是beam达到最大长度)
input_ids: 形状为(batch_size*beam_size, 1) # 全部为decoder_satrt_token
beam_scores: 形状为(batch_size, beam_size) # 其中每一行的第一个元素为0, 其余元素为-inf
beam_scores.view(-1, 1)
beam_hypotheses: batch_size个候选池
is_done: 初始化为batch_size个False
while True:
截取最后一个input_ids得到input_tensor(batch_size*beam_size, 1)
通过前向计算得到logits(batch_size*beam_size, vocab_size)后
进行log_softmax之后得到next_token_scores
next_token_scores_processed = logits_processor(input_ids, next_token_scores) # (batch_size*beam_size, vocab_size)
next_token_scores = beam_scores + next_token_scores_processed # (batch_size*beam_size, vocab_size)
next_token_scores.view(batch_size, beam_size*vocab_size)
# 对于batch中的每一个, 都留下2*beam_size个可选项(注意根据此处的规则这些可选项里至多有beam_size个eos)
next_token_scores, next_tokens = next_token_scores.topk(2*beam_size)
# 这个过程的逻辑如下:
对于每个样本
如果is_done取值为True, 则为每个beam填充pad_token, continue
从next_token_scores最大的开始
如果对应的预测token为eos:
如果此score是前beam_size大的score, 则将其加入该样本对应的候选集beam_hypotheses
加入规则如下:
如果候选池当前不足beam_size个样本, 则直接将其加入, 并计算score计算长度惩罚后,更新池子中的最差分数
如果当前候选池已有beam_size个样本, 则对此score计算长度惩罚后与池子里的score进行比较,如果优于最差分数,则加入并剔除池子里最差的那个序列, 之后更新池子的最差分数
备注: 池子中的score均为长度惩罚后的score
如果此score不是前beam_size大的score, 则直接忽略这个样本
如果对应的预测token不是eos:
将其加入到beam_scores, beam_next_tokens中直到达到beam_size个
判断beam_hypotheses是否完成,由此更新is_done
判断规则如下:
(1) 如果beam_hypotheses的模式为early_stop, 那么只要池子里有num_beam个样本, 就认为搜索结束
(2) 非early_stop模式, 则根据beam_scores中的最大者是否在计算长度惩罚后比候选池中的最差分数大, 如果更大则继续搜索(is_done=False), 如果更小则认为搜索结束(is_done=True)
beam_scores, beam_next_tokens = beam_scorer.process(input_ids, next_token_scores, next_tokens) # 逻辑见前面一大段的说明
input_ids = cat(input_ids, beam_next_tokens)
如果is_done均为True或者stopping_criteria(input_ids, scores)为True, 则跳出while True
最后做收尾:
对于还没结束的beam, 尝试添加至beam_hypotheses中
将输出序列使用pad_token补齐
group_beam_search
group_beam_search与beam_search的区别在于, 将当前的beam分为若干组, 每组group_size个序列, 每次对这个序列做beam_search, 并留下group_size个序列, 这样总共仍留有beam_size个序列
- 当 group_size 与 beam_size 相等时, 退化为beam_search
beam_sample/sample
beam_sample与beam_search的区别在于将这几行
next_token_scores_processed = logits_processor(input_ids, next_token_scores) # (batch_size*beam_size, vocab_size)
next_token_scores = beam_scores + next_token_scores_processed # (batch_size*beam_size, vocab_size)
next_token_scores.view(batch_size, beam_size*vocab_size)
next_token_scores, next_tokens = next_token_scores.topk(2*beam_size)
替换为
logit_warpper: 通常进行top-k/top-p修改分数/不修改分数, 影响后续的抽样结果
next_token_scores_processed = logits_processor(input_ids, next_token_scores) # (batch_size*beam_size, vocab_size)
next_token_scores = beam_scores + next_token_scores_processed # (batch_size*beam_size, vocab_size)
next_token_scores.view(batch_size, beam_size*vocab_size)
next_token_scores = logits_warper(input_ids, next_token_scores)
probs = nn.functional.softmax(next_token_scores, dim=-1)
next_tokens = torch.multinomial(probs, num_samples=2 * num_beams)
next_token_scores根据next_tokens的选择得到
constrained_beam_search【TODO】
<<<第一项改动>>>
对于每个样本,进行正常的beam_size得到:
beam_scores: beam_size个分数
input_ids: (beam_size, cur_len)
next_tokens: (beam_size)
对每个input_id, 根据约束计算下一步可能的token,假设增加了 H 个新的可选项,得到
full_hypo: (beam_size+H, cur_len+1) 所有的假设
full_score: (beam_size+H,) 所有假设的分数
bank: (beam_size+H,) 整数值, 对beam_size+H中每个假设计算一个满足约束的分数: 所有约束条件的最大长度*已完成的约束+进行中的约束已完成的长度
zipped = bank * 100 + full_score # 100是hf中写死的超参数
按照zipped进行从大到小排序得到indice, 并按照此顺序重排bank,得到sorted_bank,例如:
indice=[5, 4, 1, 2, 0, 3] # 即zipped中下标为5的元素最大,相应的bank值为
sorted_bank=[2, 2, 1, 0, 2, 3]
由sort_bank计算dup_num = [0, 1, 0, 0, 0, 0],dup_num为重复前一个bank值得次数
假设beam_size为3, 则最终得indice为[5, 1, 2] # 按dup_num从小到大稳定排序, 因此会跳过indice[1]
<<<第二项改动>>>
添加至hyp时需要检查是否满足条件,满足则添加,不满足则不添加
constrained_beam_search相关
class Constraint(ABC):
def __init__(self):
self.test() # 测试子类的定义是否合法
def test(self):
counter = 0
completed = False
while not completed:
if counter == 1: # 如果需要至少2步才能完成,则可以测试reset是否能正常工作
# self.reset函数语义(改变状态): 重新初始化内部的状态
self.reset()
# self.advance函数语义(不改变状态): 给出一个能满足下一步约束条件的token_id(如果有多个token_id能满足时则返回token_id列表)
advance = self.advance() # 得到一个能完成下一个步骤的token_id
# self.does_advance语义(不改变状态): 判断输入的值是否满足下一步约束的条件
if not self.does_advance(advance): # 验证一定能走到下一步
raise Exception(
"Custom Constraint is not defined correctly. self.does_advance(self.advance()) must be true."
)
# self.update语义: stepped表示当前输入是否能满足下一步的约束条件, completed为是否完全结束, reset表示是否需要重置
# 并且根据各种情况改变状态, 例如修改内部的状态或者调用self.reset
stepped, completed, reset = self.update(advance)
counter += 1
if counter > 10000:
raise Exception("update() does not fulfill the constraint.")
# self.remaining语义: 剩余步数
if self.remaining() != 0: # 在completed的时候, 剩余步数应该为0
raise Exception("Custom Constraint is not defined correctly.")
# 复制(复制当前状态/不复制当前状态)
@abstractmethod
def copy(self, stateful=False):
pass
🤗 Transformers 4.26.1 版本中目前只实现了两类 Constraint
PhrasalConstraint: 生成的结果里必须出现指定的 token_id 序列constraint = PhrasalConstraint([1, 2, 5]) # 限制输出序列必须包含连续的token序列[1, 2, 5]DisjunctiveConstraint: 生成的结果里必须出现指定的 token_id 序列(满足其中之一即可)constraint = PhrasalConstraint([[1, 2, 5], [3, 4]]) # 限制输出序列必须包含连续的token序列[1, 2, 5]或[3, 4]ConstraintListStateconstraints = [PhrasalConstraint([1, 2, 5]), PhrasalConstraint([1, 3])] ConstraintListState(constraints) # 限制输出序列必须满足多个限制条件
DisjunctiveConstraint 的实现依赖于一个辅助类, 本质上是将一个列表的列表转换为了一个字典(前缀树)
class DisjunctiveTrie:
def __init__(self, nested_token_ids: List[List[int]], no_subsets=True):
...
t = DisjunctiveTrie([[1, 2], [1, 3, 4], [1, 4, 5]])
t.trie
# {
# 1: {
# 2: {},
# 3: {4: {}},
# 4: {5: {}}
# }
# }
class ConstraintListState:
def __init__(self, constraints: List[Constraint]):
self.constraints = constraints
# max # of steps required to fulfill a given constraint
self.max_seqlen = max([c.seqlen for c in constraints])
self.n_constraints = len(constraints)
self.completed = False
self.init_state()
def init_state(self):
# complete_constraints + inprogress_constraint + pending_constraints = 全部的constraint
self.complete_constraints = []
self.inprogress_constraint = None # 只能为None或者其中一个constraint
self.pending_constraints = [constraint.copy(stateful=False) for constraint in self.constraints]
def advance(self) -> List[int]:
...
def reset(self, token_ids: Optional[List[int]]):
# 在传入token_ids参数时, 会调用self.add函数
...
def add(self, token_id: int):
# 如果inprogress_constraint为空, 则在pending_constraints找有没有能update的约束, 如果有, 就将它update并作为inprogress_constraint
# 如果inprogress_constraint不为空, 则update inprogress_constraint直至这个约束达到完成状态
return complete: bool, stepped: bool
contrastive_search【TODO: 待补充】
Huggingface 官方博客(2022/10 引入):https://huggingface.co/blog/introducing-csearch
算法伪代码如下:
首先初始化decoder的input_ids: (0,)*B
将其输入至decoder计算出 next_logits: (B, vocab_size), cur_hidden: (B, 1, d_model)
L = 1
while True:
# input_ids: 已确定序列, next_logits: 已确定序列的logits, cur_hidden: 已确定序列的decoder的输出
对next_logits进行后处理
取出next_logits中前top_k个可能的token: (B, top_k), 拼接input_ids序列 possible_input_ids: (B*top_k, L)
将possible序列作为decoder的输入, 得到 hidden: (B*top_k, d_model), new_next_logits: (B*top_k, vocab_size)
根据contrastive search的评分规则根据 next_logits, cur_hidden, hidden 挑选出每个样本最优的下一个序列 input_ids: (B, L+1)
根据input_ids挑选得到cur_hidden: (B, L+1, d_model), 挑选得到 new_next_logits: (B, vocab_size)
next_logits = new_next_logits
L += 1
判断是否达到最大长度或其他中止条件是否成立:break
返回input_ids
Streamer
通常我们必须等 generate 方法生成 eos 才能一次性拿到返回结果, 但对于大模型来说, 生成 token 的速度可能比较慢, 因此需要流式输出, 🤗 Transformers 在 4.28.0 版本左右增加了一个 API
# 官方文档示例: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.TextStreamer
from transformers import AutoModelForCausalLM, AutoTokenizer, TextStreamer, TextIteratorStreamer
tok = AutoTokenizer.from_pretrained("gpt2")
model = AutoModelForCausalLM.from_pretrained("gpt2")
inputs = tok(["An increasing sequence: one,"], return_tensors="pt")
streamer = TextStreamer(tok)
# Despite returning the usual output, the streamer will also print the generated text to stdout.
_ = model.generate(**inputs, streamer=streamer, max_new_tokens=20)
# 官方文档示例: https://huggingface.co/docs/transformers/internal/generation_utils#transformers.TextIteratorStreamer
# 主要用于 Gradio
from threading import Thread
tok = AutoTokenizer.from_pretrained("gpt2")
streamer = TextIteratorStreamer(tok)
# Run the generation in a separate thread, so that we can fetch the generated text in a non-blocking way.
generation_kwargs = dict(inputs, streamer=streamer, max_new_tokens=20)
thread = Thread(target=model.generate, kwargs=generation_kwargs) # 新开一个线程用于产生token, token被put到streamer内部的queue.Queue中
thread.start()
generated_text = ""
for new_text in streamer: # 主线程从streamer内部的queue.Queue取数据
generated_text += new_text
generated_text
内部逻辑其实比较简单, Streamer 相关的 API 仅有如下 3 个
注意: 目前只能用于 batch_size 为 1 的情形, 并且不能用于 beam_size > 1
# transformers/generation/streamers.py
class BaseStreamer:
def put(self, value):
# value 是一个一维tensor, 或者第0维为1的二维tensor, 代表token_id序列
raise NotImplementError()
def end(self):
raise NotImplementError()
class TextStreamer(BaseStreamer):
...
class TextIteratorStreamer(TextStreamer):
...
在 🤗 Transformers 的 generate 中, 使用 Streamer 的逻辑是: 首先调用 put 将 prompt 推入 Streamer 中, 每次生成了一个新的 token 之后, 将新生成的 token 推入 Streamer 中(如果是TextStreamer, 则打印最新的完整word), 生成结束后, 调用 end 方法
以下是一个相对独立地使用 TextStreamer 的例子, 供参考
from transformers import AutoTokenizer, TextStreamer
tokenizer = AutoTokenizer.from_pretrained("gpt2")
streamer = TextIteratorStreamer(tokenizer)
text = "A B C D E F"
tokens = tokenizer(text, return_tensors="pt")["input_ids"][0]
import time
import random
cur_idx = 0
n = len(tokens)
while True:
num = random.randint(1, 3)
end = cur_idx + num
streamer.put(token[cur_idx:end])
cur_idx = num
time.sleep(0.2)
if end >= n:
streamer.end()
break
AutoClass: AutoModel, AutoTokenizer, AutoConfig
本节内容的出发点在于解释这类代码在执行时究竟发生了什么
from transformers import AutoModelForCausalLM
# 这里是 transformer 4.32.0 版本才有的 AutoGPTQ 集成的模型
model = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto")
这涉及到 Auto 类的实现, 相应的代码位于 src/transformers/models/auto 文件夹下:
src/transformers/models/
- auto/
- __init__.py
- auto_factory.py
- configuration_auto.py
- modeling_auto.py
- tokenization_auto.py
# 以下本节不涉及
- feature_extraction_auto.py
- image_processing_auto.py
- processing_auto.py
- modeling_flax_auto.py
- modeling_tf_auto.py
- deprecated/ # 一些弃用的模型代码
- open_llama/ # 目录结构与其他模型例如 bert 一致
- bert/
- bart/
Auto 类如下:
- AutoTokenizer: 直接继承自 object
- AutoConfig: 直接继承自 object
- _BaseAutoModelClass: 直接继承自 object
- AutoModelForMaskedLM: 父类为 _BaseAutoModelClass
- AutoModelForCausalLM: 父类为 _BaseAutoModelClass
- …
为此我们先看看 transformers/models/auto 相关代码里硬编码写的一些字典映射, 这种字典的键和值有如下类型:
- model-type: 可以用中划线或下划线连接, 例如
"deberta-v2" - model-display-name: 可以用空格连接, 例如
"Audio Spectrogram Transformer", 对应于文档页面上的模型名称 - module-name: 这种在字典映射中不直接出现, 大多数情况下使用下划线代替 model-type 中的中划线即为 module-name, 例如
"deberta_v2", 对应于目录结构src/transformers/models/deberta_v2 - model-class-name: 例如
"LlamaForCausalLM", 对应于类名src/transformers/models/llama/modeling_llama.py:LlamaForCausalLM - config-class-name: 例如
"LlamaConfig", 对应于类名src/transformers/models/llama/configuration_llama.py:LlamaConfig - slow-tokenizer-class-name: 例如
"LlamaTokenizer", 对应于类名src/transformers/models/llama/tokenization_llama.py:LlamaTokenizer - fast-tokenizer-class-name: 例如
"LlamaTokenizerFast", 对应于类名src/transformers/models/llama/tokenization_llama_fast.py:LlamaTokenizerFast
相关的字典映射具体如下:
AutoTokenizer 相关 |
AutoConfig 相关 |
AutoModel 相关 |
Auto 类及相关的辅助方法(即上述三个文件里的其余内容)如下:
AutoTokenizer 相关 |
AutoConfig 相关 |
AutoModel 相关 |
在深入之前, 这里先简单提及一下上面所有 Auto 类的特点:
- 它们均不能实例化, 一般使用
from_pretrained方法返回的是一个具体的类的实例, 例如:AutoConfig.from_pretrained(...)可能返回的是LlamaConfig的实例AutoTokenizer.from_pretrained(...)可能返回的是LlamaTokenizer的实例AutoModelForCausalLM.from_pretrained(...)可能返回的是LlamaForCausalLM的实例
- 每个 Auto 类都绑定了一个“字典”, 例如:
AutoConfig: 绑定了CONFIG_MAPPINGAutoTokenizer: 绑定了TOKENIZER_MAPPINGAutoModel: 绑定了MODEL_MAPPINGAutoModelForCausalLM: 绑定了MODEL_FOR_CAUSAL_LM_MAPPING
下面回到最开始的出发点, 解释各个 Auto 类 from_pretrained 时究竟发生了什么
AutoModel
# transformers/models/auto/modeling_auto.py
MODEL_FOR_CAUSAL_LM_MAPPING = _LazyAutoMapping(CONFIG_MAPPING_NAMES, MODEL_FOR_CAUSAL_LM_MAPPING_NAMES)
class AutoModelForCausalLM(_BaseAutoModelClass):
_model_mapping = MODEL_FOR_CAUSAL_LM_MAPPING
AutoModelForCausalLM = auto_class_update(AutoModelForCausalLM, head_doc="causal language modeling")
因此接下来需要研究如下几个东西:
_LazyAutoMapping: 这个类的实例主要是TOKENIZER_MAPPING,MODEL_MAPPING,MODEL_FOR_CAUSAL_LM_MAPPING等_BaseAutoModelClassauto_class_update
_LazyAutoMapping
本质上 _LazyAutoMapping 是一个字典, 在使用上:
- 键:
config-class, 注意是类不是字符串, 例如transformers.models.bert.BertConfig - 值:
model-class或tokenizer-class, 注意是类不是字符串
这一过程是动态的, 因为不同的模型/tokenizer可能有不同的依赖包, 动态添加可以只加载与使用的模型相关的模块, 例如在使用 bert 相关的代码时, 只会加载 transformers.models.bert 模块, 而不会加载其他模块
测试代码 1:
import transformers
from transformers import TOKENIZER_MAPPING, MODEL_MAPPING, MODEL_FOR_CAUSAL_LM_MAPPING
TOKENIZER_MAPPING[transformers.models.bert.BertConfig]
# (transformers.models.bert.tokenization_bert.BertTokenizer, transformers.models.bert.tokenization_bert_fast.BertTokenizerFast)
# 注意目前加载的模块只有一个, 其他几个 MAPPING 同理
TOKENIZER_MAPPING._modules
# {'bert': <module 'transformers.models.bert' from `xx/yy.py`}
MODEL_MAPPING[transformers.models.bert.BertConfig]
# transformers.models.bert.modeling_bert.BertModel
MODEL_FOR_CAUSAL_LM_MAPPING[transformers.models.bert.BertConfig]
# transformers.models.bert.modeling_bert.BertLMHeadModel
测试代码 2:
import transformers
from transformers import TOKENIZER_MAPPING, MODEL_MAPPING, MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING
# from transformers.models.bert import BertForSequenceClassification
# model = BertForSequenceClassification.from_pretrained("./chinese-roberta-wwm-ext")
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("./chinese-roberta-wwm-ext")
# 上面两种情况下, 输出分别是
print(MODEL_MAPPING._modules) # {}, {}
print(TOKENIZER_MAPPING._modules) # {}, {}
print(MODEL_FOR_SEQUENCE_CLASSIFICATION_MAPPING._modules) # {}, {"albert": transformers.models.albert}
# sys.modules 的内容待探究
以下是 _LazyAutoMapping 类的关键源码
# config-class -> model-class/tokenizer-class
class _LazyAutoMapping(OrderedDict):
def __init__(self, config_mapping, model_mapping):
self._config_mapping = config_mapping # model-type -> config-class-name
self._reverse_config_mapping = {v: k for k, v in config_mapping.items()} # config-class-name -> model-type
self._model_mapping = model_mapping # model-type -> model-class-name / (slow-tokenizer-class-name, fast-tokenizer-class-name)
self._model_mapping._model_mapping = self
# 调用 register 方法时添加
self._extra_content = {} # config-class -> model-class/tokenizer-class
# 调用 __getitem__ 方法时动态加载相应的 module
self._modules = {} # module-name -> module
def __len__(self):
common_keys = set(self._config_mapping.keys()).intersection(self._model_mapping.keys())
return len(common_keys) + len(self._extra_content)
def __getitem__(self, key):
if key in self._extra_content:
return self._extra_content[key]
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping:
model_name = self._model_mapping[model_type]
return self._load_attr_from_module(model_type, model_name)
# Maybe there was several model types associated with this config.
model_types = [k for k, v in self._config_mapping.items() if v == key.__name__]
for mtype in model_types:
if mtype in self._model_mapping:
model_name = self._model_mapping[mtype]
return self._load_attr_from_module(mtype, model_name)
raise KeyError(key)
def _load_attr_from_module(self, model_type, attr):
module_name = model_type_to_module_name(model_type)
if module_name not in self._modules:
self._modules[module_name] = importlib.import_module(f".{module_name}", "transformers.models")
return getattribute_from_module(self._modules[module_name], attr)
def keys(self): pass
def get(self, key, default): pass
def __bool__(self): pass
def values(self): pass
def items(self): pass
def __iter__(self): pass
def __contains__(self, item): pass
def register(self, key, value, exist_ok=False):
if hasattr(key, "__name__") and key.__name__ in self._reverse_config_mapping:
model_type = self._reverse_config_mapping[key.__name__]
if model_type in self._model_mapping.keys() and not exist_ok:
raise ValueError(f"'{key}' is already used by a Transformers model.")
self._extra_content[key] = value
_BaseAutoModelClass
auto_class_update
def auto_class_update(cls, checkpoint_for_example="bert-base-cased", head_doc=""):
# Create a new class with the right name from the base class
model_mapping = cls._model_mapping
name = cls.__name__
class_docstring = insert_head_doc(CLASS_DOCSTRING, head_doc=head_doc)
cls.__doc__ = class_docstring.replace("BaseAutoModelClass", name)
# Now we need to copy and re-register `from_config` and `from_pretrained` as class methods otherwise we can't
# have a specific docstrings for them.
from_config = copy_func(_BaseAutoModelClass.from_config)
from_config_docstring = insert_head_doc(FROM_CONFIG_DOCSTRING, head_doc=head_doc)
from_config_docstring = from_config_docstring.replace("BaseAutoModelClass", name)
from_config_docstring = from_config_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
from_config.__doc__ = from_config_docstring
from_config = replace_list_option_in_docstrings(model_mapping._model_mapping, use_model_types=False)(from_config)
cls.from_config = classmethod(from_config)
if name.startswith("TF"):
from_pretrained_docstring = FROM_PRETRAINED_TF_DOCSTRING
elif name.startswith("Flax"):
from_pretrained_docstring = FROM_PRETRAINED_FLAX_DOCSTRING
else:
from_pretrained_docstring = FROM_PRETRAINED_TORCH_DOCSTRING
from_pretrained = copy_func(_BaseAutoModelClass.from_pretrained)
from_pretrained_docstring = insert_head_doc(from_pretrained_docstring, head_doc=head_doc)
from_pretrained_docstring = from_pretrained_docstring.replace("BaseAutoModelClass", name)
from_pretrained_docstring = from_pretrained_docstring.replace("checkpoint_placeholder", checkpoint_for_example)
shortcut = checkpoint_for_example.split("/")[-1].split("-")[0]
from_pretrained_docstring = from_pretrained_docstring.replace("shortcut_placeholder", shortcut)
from_pretrained.__doc__ = from_pretrained_docstring
from_pretrained = replace_list_option_in_docstrings(model_mapping._model_mapping)(from_pretrained)
cls.from_pretrained = classmethod(from_pretrained)
return cls
Trainer【TODO: 考虑移除】
Pipeline【TODO: 考虑移除】
后记【TODO】
本文原本只是想理清 T5 预训练、微调、推理的细节。因此有必要基于这条主线对全文的行文进行梳理
- 怎么预训练 T5
- C4 数据集
- 怎么训练一个 tokenizer
- 训练一个 T5Tokenizer/T5TokenizerFast
- 怎么使用 tokenizer
- 预训练脚本
- 🤗 Datasets 或自定义 torch.data.utils.Dataset
- 🤗 Transformers Trainer 或 raw pytorch 或 raw pytorch with 🤗 Accelerate 或 Lightning 或 deepspeed
- 微调 T5
- 微调数据集
- 微调脚本
- T5 推理
- 怎么生成文本
- 生成策略及参数的含义
- pipeline
- 怎么生成文本
主要参考资料【TODO】
-
Huggingface 官方课程: course
- Transformer 模型结构
- Huggingface 官方博客,介绍 encoder-decoder 架构:encoder-decoder
- 图解 Transformer 的一篇博客(强力推荐):illustrated-transformer,中文翻译版
- 代码实现 Transformer 的一篇博客(哈佛出品,强力推荐): 原版,更新版
- tokenizer
- 🤗 Transformers 官方文档对各个模型所使用的 tokenizer 的概述:官方文档
- 🤗 nlp course: chapter 6
- BPE
- BPE 算法详解博客:博客
- Unigram/SentencePiece:
- 杂项
- 机器翻译里不能用 word 当作词表的原因及解决方法简介:open vocabulary problem in neural machine translation(NMT)